Constructing a Dimensional Environment with Oracle Database and ODI 12c
Learn how you can construct a dimensional environment for answering business questions.
By Yuli Vasiliev
No matter what you’re using it for, Business Intelligence (BI) is ultimately about deriving necessary information from an organization's data, getting your business questions answered. And although both a business question and its answer are normally formulated in plain English, the process of transition from the first to the second often relies on a set of more sophisticated tools than just plain English. If you are not new to databases, you should have some experience on how to derive necessary information from data with the help of SQL queries
However, the approach based on using SQL queries directly may not be so efficient when it comes to performing analysis of aggregated data. The problem is not only that such queries may be quite complicated to compose, but also that the data you need to query may be stored in heterogeneous sources, and in different formats. Thus, you may need to perform data transformation and synchronization to ensure that the information you obtain is accurate and consistent across all the sources, with respect to a single point in time. To meet these challenges, Oracle offers comprehensive data integration solutions, such as Oracle Data Integrator.
Returning to business questions asked against an organization's data, they are, in most cases, multidimensional requests, where a dimension is a category – such as time, product, or department – used in specifying those questions. So, such requests usually involve multiple dimensions and require aggregated fact data that might be, for example, last quarter’s sales figures, profits by product and by provider, or year-to-date production volumes. Logically, multidimensional data can be viewed as a cube in which fact data is organized by dimensions. However, the physical implementation involves a bunch of objects stored normally in the underlying database, including fact tables and dimension tables. The process of designing a dimensional data model and its implementation can be significantly simplified with tools such as Oracle Data Integrator (ODI).
This article contains a sample that illustrates a simple example of a dimensional environment you can build on top of an Oracle database with Oracle Data Integrator 12c.
On Multidimensional Analysis
As its name implies, multidimensional analysis applies to the data organized across multiple dimensions, such as regions, products, time periods, customers, and departments. Although a multidimensional data object may be organized across more than three dimensions, it is often referred to as a cube.
The diagram in the figure below provides a graphical representation of such a cube:

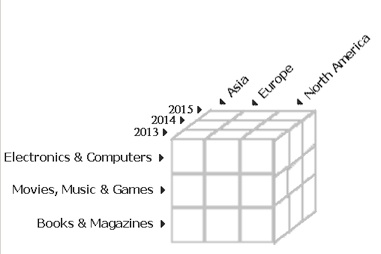
Figure 1: A typical example of a logical cube representing a multidimensional data structure.
Of course, the above is a generalized view of a multidimensional data object. Forming the edges of a logical cube, dimensions, in most cases, are level-based, meaning they consist of a set of levels grouped into hierarchies. For example, a hierarchy for Time dimension may include a number of levels, including year, quarter, month, week, day, hour, minute, and even second. The level of granularity you might want to choose for a dimension depends on your business needs, of course. For example, a trade company interested in analyzing the sales of its products over time may want to have analysis on a daily, monthly, and yearly basis, meaning you’ll need a Time dimension hierarchy that allows drilling down to day-to-day sales activities. In areas like televoting however, analysts might prefer to view the incoming calls aggregated into seconds, minutes or hours, thus requiring the seconds level in a time dimension as the lowest level of aggregation.
Questions To Answer
It all starts with the questions you want to get answered through analyzing your business data. This is because the questions impact the way in which you collect, organize and prepare data for analysis. The easiest way to see how it works is by example.
Let’s say you run a retail Website that sells different types of products around the world. So, what questions regarding the state of your business might you have? A common set of such questions could include the following ones:
-
What are our top ten best selling products for the last summer?
-
What are our top three most profitable product segments?
-
Customers from what country yielded highest revenue for the last three months?
While the above look like pretty standard questions, your team may be interested in more specific ones. For example, if you sell clothes, you might be interested in knowing what sizes are most common in countries where you have local warehouses – to fill them up in accordance with that demand. For this same reason, you may also be interested in seeing how style and color preferences in clothes can be projected to the geographical map.
Anyway, after you have a defined set of questions to be answered, you can figure out how the data for analysis should be organized to fulfill your needs.
Deciding On Dimensions
The next step on the way from questions to answers is to design a dimensional model for your data. For that, you’ll you need to decide on the dimensional objects to be used, including cubes, measures, dimensions, levels, and hierarchies. For this simple example, your dimensional model may include a single cube with several dimensions. Examining the list of questions provided in the preceding section, you might want to use the following dimensions to organize the data in the cube:
-
Geography organizes the data related to the geography locations the purchase orders come from
-
Products categorizes the sold products
-
Time aggregates purchase orders data across time
Now you need to decide on the levels of data aggregation for each dimension, putting those levels into hierarchies. So, the hierarchy of levels for the Geography dimension might look like this
For the Products dimension, you might define the following levels (in practice, of course, there may be more group levels in this category):
And the Time dimension might contain the following level hierarchy:
It is important to note that a dimension may be associated with more than one hierarchy. In this particular example however, each dimension is tied to a single level hierarchy.
Data Sources To Be Used
Building a dimensional environment for business analysis is not only limited to designing dimensional structures for your data, but also implies that you may need to acquire diverse data sources, transforming and synchronizing the obtained data. As it is often the case with online retailers, you may have separate websites for each country you operate in. Moreover, even a single Web interface the users get used to see within the same country may be backed by several different servers, which are not always running on the same platform and using the same underlying software. So, the storage types for the data being collected also may vary greatly – often, from a relational database to flat files.
For this particular example however, suppose you have a single data source containing fact data for your data model in the PurchaseOrders.dmp file coming with Oracle Database 12c as a sample. This file contains 10000 sample PO documents in JSON format, and can be found in the following directory: $ORACLE_HOME/demo/schema/order_entry, assuming you have an Oracle Database 12c installed on your computer.
Preparing Your Working Environment
Now that you have decided what objects you need to work with, it’s time to move on to the physical implementation, where the first step is preparing your working environment. Although all those objects will be defined in an Oracle database, you’re not going to do it manually but using a special solution for this.
Actually, Oracle offers several data integration solutions you can use to build and maintain a multi-dimensional environment for business analysis purposes. Until recently, the most popular one was Oracle Warehouse Builder (OWB) shipped pre-installed with Oracle Database. Starting with Oracle Database 12c however, OWB is no longer shipped with the database. Although you can still use OWB 11gR2 with Oracle Database 12c, Oracle recommends you to switch to Oracle Data Integrator – Oracle’s strategic Data Integration offering at the moment.
To follow the example provided in this article, you’ll need the following software:
If you don’t have them already installed, the quickest way to get started is to take advantage of the Oracle Data Integrator 12c VM for Oracle VM VirtualBox. So, the first step is to download and install Oracle VM VirtualBox (if you don't have it yet), which is currently available for Windows, Mac OS X, Linux and Solaris operating systems. Next, you can download and then install the Oracle Data Integrator 12c VM appliance within the Oracle VM VirtualBox. The entire process usually takes a few minutes, after which you will have ready-to-use installations of Oracle EE Database 11.2 and Oracle Data Integrator 12.1, pre-configured to work together. The other software components included in this appliance are Oracle GoldenGate 12.1 and Java Platform (JDK) 1.7. At the time you read this article, there may be a newer version of the ODI appliance available for download from the Pre-Built Developer VMs for Oracle VM VirtualBox page of the Oracle Technology Network (OTN) website.
Implementation with Oracle Data Integrator 12c
Continuing with our simple example from above, let’s first outline the general tasks to be accomplished. Listed as short bullets, they might look as follows:
-
Consolidating data from the data sources
-
Implementing the dimensional objects: dimensions and cube
-
Loading data extracted from the sources into the dimensional objects
To accomplish these tasks, you’ll need ODI Studio and SQL Developer or a similar tool to interact with an underlying Oracle database directly.
A more specific list of tasks to be done includes:
In SQL Developer:
- Creating SQL definitions for the dimensions tables and the fact table in the underlying database.
In ODI Studio:
-
Creating ODI definitions for the data source.
-
Creating ODI definitions for the dimensions and the fact datastores.
-
Creating a mapping that organizes the data flow from the source to the fact datastore.
-
Running the mapping.
Creating a New Project in ODI 12c
Strictly speaking, it is not mandatory to start with creating a new project in ODI Studio when you begin a new work. You might start, for example, with defining physical and logical architectures for the source and the target, and then define their models, proceeding to create a new designer project only then. However, in light of keeping things in a logical order, starting a new work in a GUI with creating a new project in that tool sounds quite reasonable.
Before proceeding to a new project in ODI Studio, make sure you have already installed and configured ODI Master repository and Work repository. For details, you can refer to Oracle Fusion Middleware Installing and Configuring Oracle Data Integrator. However, if you’re using the Oracle Data Integrator 12c VM for Oracle VM VirtualBox mentioned in the Preparing Your Working Environment section earlier, the ODI installation includes these repositories pre-installed.
The following steps walk you through the process of creating a blank project in ODI Studio. (For a more detailed example of creating a project in ODI, you can refer to Oracle Learning Library; for example, Oracle Data Integrator 12c - Creating an ODI Project and Mapping: Flat File to a Table)
1. Launch ODI Studio by running script odi.sh from the $ODI_HOME/studio folder. If on Windows, run script odi.exe from the same folder, instead.
2. On the Designer tab in ODI Studio, click Connect To Repository...
3. In the Enter Wallet Password dialog, enter the wallet password (in case of the Oracle Data Integrator 12c VM, the password is pre-stored: welcome1).

_Figure 2: Entering the wallet password_
4. In the Oracle Data Integrator Login dialog, click the New button (with the Plus icon on it) to create a new login name you will use for the project.
5. In the Repository Connection Information dialog, fill in the fields as in the figure below (in case of the Oracle Data Integrator 12c VM, the password for the SUPERVISOR user is set to SUPERVISOR, and the password for the prod_odi_repo user is set to oracle).
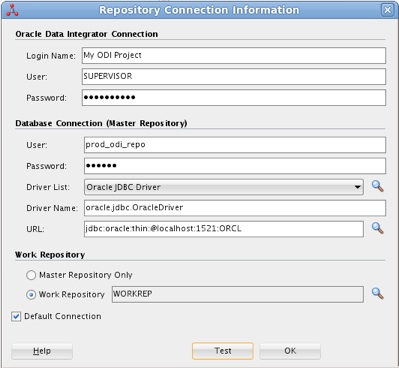
Figure 3: Creating a new repository connection
6. To make sure a new connection is working, click the Test button in the Repository Connection Information dialog. If successful, click OK to save the new login name.
7. In the Oracle Data Integrator Login dialog, choose My ODI Project in the Login Name box and click OK.
8. In the Designer tab, click the New Project button and then select New Project in the popup menu.
9. On the Project panel, in the Name field enter a project name, which is automatically copied into the Code field below.

Figure 4: Creating a new project in ODI Studio
10. On the main pane of ODI Studio, click the Save button to save your work.
You’ll come back to the MY-ODI-PR project just created later, when it comes to defining the project mapping.
Including JSON as a Source in ODI 12c
As mentioned, the fact data for the data model of the sample discussed here will be taken from a JSON data source, which can be interesting on its own since illustrates JSON support (new feature of ODI 12c) in action. In particular, the data will be taken from the PurchaseOrders.dmp dump file that comes with Oracle Database 12c as a sample.
Generally speaking, to include a JSON dataset as a data source in ODI 12c, you need to perform the following two tasks:
Setting up the topology in turn requires you to perform the following two tasks:
The following steps and screenshots walk you through the entire process of including the PurchaseOrders.dmp dump file as a source in ODI 12c:
- In ODI Studio on the Topology tab, expand the Physical Architecture/Technologies node, and right-click Complex File, then select New Data Server.
Figure 5: Creating a Data Server for the Complex File Technology
2. On the Definition tab, enter the name for the data server being created; for example: json_file.
3. On the JDBC tab, click the magnifying glass button on the right of the JDBC Driver field and select oracle.odi.jdbc.driver.file.complex.ComplexFileDriver.
4. Next, click the Edit nXSD... button on the right of the JDBC URL field to launch the Native Format Builder.
Figure 6: The Welcome screen of the Native Format Builder

Before continuing, you need to do some work on the source file. As mentioned, PurchaseOrders.dmp used as the source here contains 10000 sample purchase order documents in JSON format – all are structurally identical. However, the Native Format Builder requires a single JSON document to generate an nXSD file. Moreover, a JSON document to be used by the builder cannot include gaps in the names of attributes.
5. Leave for a while ODI Studio, and find the PurchaseOrders.dmp file on your computer. As mentioned, it comes with Oracle Database 12c as a sample, and can be found in $ORACLE_HOME/demo/schema/order_entry. Open the file with a text editor and copy a single PO document from it; for example, PONumber 1, to the clipboard. Then, create a new blank file; for example, OnePurchaseOrder.dmp, and insert the copied PO there. Edit the document, removing the gap in the Special Instructions attribute name to avoid problems when generating an nXSD file. Also make sure to alter this attribute name throughout each PO in PurchaseOrders.dmp. Employ the Replace tool of your editor to automate the task.
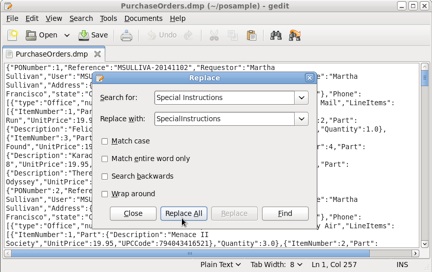
Figure 7: Replacing an attribute name throughout each P.O. in PurchaseOrders.dmp.
6. Turn back to the Native Format Builder launched in ODI Studio. On the File Name and Directory screen, enter a file name for the nXSD being created; for example, nxsd_json.xsd, and select a directory to save it in.
7. On the Choose Type screen of the builder, choose JSON Interchange Format as the file type.
8. On the JSON File Description screen of the builder, click Browse on the right of the File name field and select OnePurchaseOrder.dmp file created in step 5 earlier. Then, go down to the Root element field and change its value to POrders.
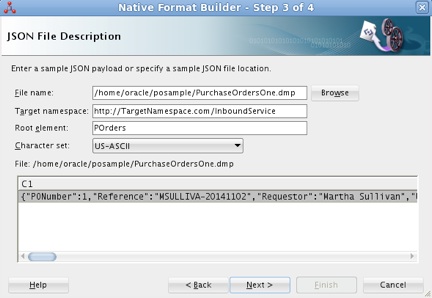
Figure 8: The JSON File Description screen of the builder
The Native Format Builder allows you make manual changes to an XSD document it generates, if necessary. In this particular case, you have to change the type of the UPCCode element from xsd:integer to xsd:long, because the values of this element are too large for integer.
9. On the next screen of the builder, you should see the native format file generated. This is an XSD document available for making manual changes. So, look through it and find the following line: <xsd:element name="UPCCode" type="xsd:integer"/>. Change the type from xsd:integer to xsd:long as follows: <xsd:element name="UPCCode" type="xsd:long"/>
10. After completing the builder, you should be on the JDBC tab of the json_file panel again. Here, enter the following line in the JDBC URL line: jdbc:snps:complexfile?f=/home/oracle/posample/PurchaseOrders.dmp&d=/home/oracle/posample/nxsd_json.xsd&re=POrders. Your actual paths may be different, of course. Note, however, that the f parameter refers to the PurchaseOrders.dmp file containing 10000 PO documents, rather than to OnePurchaseOrder.dmp containing a single document, which you created just to build an nXSD file with the builder.
11. On the JDBC tab of the json_file panel, go down to the Properties box, and scroll down to the dp_numeric_lenght property. Turn off the Use Default for this property, and then set it manually to 14.
12. From the main menu of ODI Studio, select File->Save to save the newly created data server.
13. To make sure everything is OK so far, click the Test Connection button in the top-left corner of the json_file panel. In the Test Connection for: json_file dialog, click Test. If everything is OK, the Succesful Connection message should appear after a while.
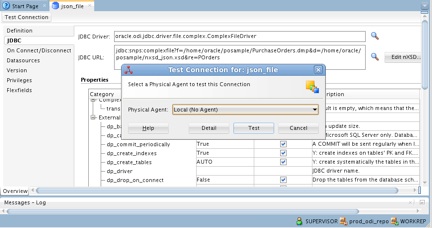
Figure 9: Testing a connection to the data server just created
14. In the next step, you need to define a physical schema for the json_file data server just created. For that, right-click json_file on the Topology tab, and select New Physical Schema.
15. On the json_file.Schema panel, in Schema(Schema) and in Schema(Work Schema), select a schema from the drop-down list.
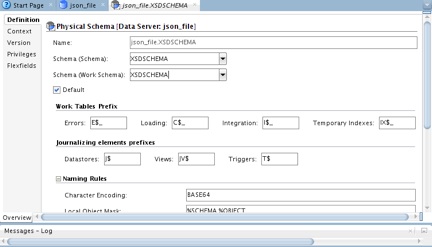
Figure 10: Defining a physical schema for the data server.
16. From the main menu of ODI Studio, select File->Save to save the physical schema for the json_file data server.
Finally, you have to define a logical schema on top of the physical schema just created.
17. On the Topology tab, expand the Logical Architecture/Technologies node, and right-click Complex File, then select New Logical Schema.
18. On the Definition tab of the Logical Schema panel, enter a Name; for example: POrders. Under Physical Schemas, choose the physical schema defined in these steps earlier.
19. From the main menu of ODI Studio, select File->Save to save the logical schema just defined.
Now that you have defined the topology, you can proceed to define a model based on it.
20. On the Designer tab, click the New Model Folder button on the right of Models and then select New Model Folder from the menu.
21. In a new Model Folder panel opened on the right, enter a name for the folder being created; for example, POrders.
22. From the main menu of ODI Studio, select File->Save to make the newly created folder available under the Models node on the left.
23. On the Designer tab, expand Models and right-click the folder created in the preceding step, then select New Model from the menu.
24. On the Definition tab of the Model panel, enter a name in the Name field; for example, JSON_POs. Also, choose Complex File in the Technology pull-down, and POrders in the Logical Schema pull-down.
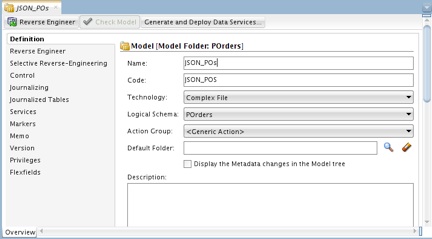
Figure 11: Defining a model based on the topology.
25. On the Reverse Engineer tab of the Model panel, click the Reverse Engineer button to launch a reverse-engineering process. This can take a while. Finally, you should see a number of datastores under the JSON_POs model, including the following tables: ADDRESS, LINEITEMS, PART, PHONE, PORDERS, and SHIPPINGINSTRUCTIONS.
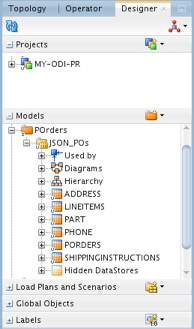
Figure 12: The model is populated with datastores as a result of reverse engineering.

For testing purposes, you can right-click any of these datastores and select View Data to look at the data it is populated with.
Creating SQL Definitions for the Dimensions
As you've seen, the reverse-engineering process for the source model described in the preceding section resulted in creating several datastores, or, simply put, several related tables in the underlying database. This can be thought of as a result of shredding the JSON data derived from PurchaseOrders.dmp into relational data.
With those tables in place however, there are still some missed parts required to build a simplest data warehouse schema for the article sample. Thus, you also need to define datastores that will represent the dimensions in the sample data warehouse. If you recall from the earlier section Deciding On Dimensions, there are three dimensions that need to be defined: Geography, Products, and Time. Let’s take a closer look at each of them before going any further.
Examining the JSON PO document structure from PurchaseOrders.dmp, you may notice that it contains field country in the Address object. If you recall, the hierarchy of levels for the Geography dimension defined in the Deciding On Dimensions section earlier in this article include Region and Country. What this means is that you can define a datastore with those two attributes: Region and Country, using the latter as the primary key one. This will be discussed in detail later in this section.
Meanwhile, let’s take a look at the Products dimension also mentioned in the Deciding On Dimensions section earlier. Going back to the PO JSON document from PurchaseOrders.dmp, take a look at the LineItems array that contains Part objects, each of which represents a product sold in a PO document. As you may notice, a Part object does not contain a category attribute, which would allow you to categorize the products. So, let’s evaluate what it would take to add such information yourself.
When shredded into relational data as discussed in the preceding section, the Part objects derived from PurchaseOrders.dmp turn into relational rows in the Part table. The row count query issued against this table shows it contains 45260 rows. Even if you eliminate duplicate parts, using the DISTINCT qualifier when counting the DESCRIPTION_ column in the Part table, as follows:
SELECT count(distinct description_) FROM xsdschema.part
Note: An easy way of issuing a query inside ODI Studio is through the New Query dialog, which you can invoke by clicking the New Query button in the Data panel's toolbar.

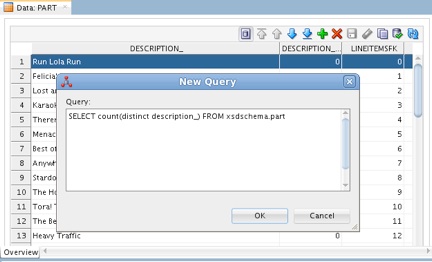
Figure 13: Issuing a custom query from inside ODI Studio.
You still get 5166 unique part records. Obviously, it would be too tedious to manually process that number of rows, adding a category to each one. For comparison, you’ll need to insert only four rows into the underlying table when defining the Geography dimension, assigning a region to a country. So it sounds reasonable to abandon the Products dimension for this example to avoid the time-consuming task of having to insert so many rows into the dimension’s underlying table.
Finally, you’ll need to define the Time dimension described in the Deciding On Dimensions section. This will be described in detail below.
So, what you need to do now is to define two dimensions: Geography and Time. You start with creating SQL definitions for them in the underlying database. Assuming you have an Oracle database installed, follow the steps below:
1. Launch SQL Developer or SQLPLUS, and sign on with DBA privileges using an account such as sys or system.
2. Create the MY_ODI_PR schema and grant necessary privileges, by issuing the following commands:
CREATE USER MY_ODI_PR IDENTIFIED BY pswd;
GRANT CONNECT, RESOURCE TO MY_ODI_PR;
3. Connect as MY_ODI_PR, and create the geography_dm table as follows:
CREATE TABLE my_odi_pr.geography_dm(
country VARCHAR2(50),
region VARCHAR2(50),
CONSTRAINT geography\_dm\_\_pk PRIMARY KEY(country)
);
4. Then, populate the geography_dm table with data:
INSERT INTO my_odi_pr.geography_dm VALUES('United States of America', 'North America');
INSERT INTO my_odi_pr.geography_dm VALUES('Canada', 'North America');
INSERT INTO my_odi_pr.geography_dm VALUES('United Kingdom', 'Europe');
INSERT INTO my_odi_pr.geography_dm VALUES('Germany', 'Europe');
COMMIT;
5. The next step is to create the time_dm table:
CREATE TABLE my_odi_pr.time_dm(
date_id number constraint time_dm_pk primary key,
full_date date not null,
month number not null,
year number not null
);
6. Before populating it however, you need to determine the date range in which the sample orders were issued. This can be done with the following two queries, deriving the dates from the reference attribute in the porders table:
Note: You can issue these queries within the New Query dialog invoked by clicking New Query on the Data:PORDERS panel's toolbar.
select MAX(TO_DATE(SUBSTR(reference, INSTR(reference, '-')+1 ,8),
'YYYYMMDD')) from XSDSCHEMA.PORDERS
2014-12-31 00:00:00.0
select MIN(TO_DATE(SUBSTR(reference, INSTR(reference, '-')+1 ,8),
'YYYYMMDD')) from XSDSCHEMA.PORDERS
2014-01-01 00:00:00.0
7. As you can see, all the orders stored in the porders table were issued in 2014. Therefore, you need to populate the time_dm table so that each record represents a day in that year. This can be done with the following PL/SQL code:
DECLARE
start_date date;
end_date date;
month number;
BEGIN
start_date:=to_date('01-01-2014','DD-MM-YYYY');
FOR i IN 1..12 LOOP
month:=i;
end_date:=last_day(start_date);
while start_date<=end_date loop
insert into my\_odi\_pr.time\_dm values(to\_number(to\_char(start\_date, 'yyyymmdd')),start\_date,month,2014);
start\_date:=start\_date+1;
end loop;
END LOOP;
END;
COMMIT;
8. To verify it has worked as expected, you can issue the following query:
SELECT count(*) FROM time_dm;
Which should generate the following result:
365
Showing the number of records for one year period with detalization at day level.
Now that you have the SQL definitions for the sample dimensions, you can proceed to create ODI definitions for them. Before doing so, let’s create the fact table in the underlying database to finish with SQL definitions for this sample.
Creating the Fact Table in the Underlying Database
To be able to organize the sample sales data into a logical cube, you need to define a fact table (actually, each cube must have a fact table). In our ODI model, the fact table will be a target datastore deriving the data from the tables generated by ODI Studio in the process of reverse-engineering of the PurchaseOrders.dmp file data source. Apart from that, the fact table has to include foreign keys to the dimension tables.
So, connect as MY_ODI_PR to the underlying database, and create the sales_fact table as follows:
CREATE TABLE my_odi_pr.sales_fact(
id number,
date_id number,
country VARCHAR2(255),
description_ VARCHAR2(500),
amount number(16,2),
CONSTRAINT sales_fact_pk PRIMARY KEY(id, date_id, country)
);
Note: Being a fact table, it is supposed to be queried by end users - consumers.
Creating the ODI Definitions for the Dimensions and the Fact Table
After creating the SQL definitions for the dimensions and the fact table, you can go ahead and define a physical architecture for those definitions in ODI Studio. The steps below will walk you through the entire process:
1. In ODI Studio, on the Topology tab, expand the Physical Architecture->Technologies node, and right-click Oracle, then select New Data Server.
2. On the Definition tab of the Data Server panel, enter the name for the data server being created; for example: po_target. Then, enter orcl in the Instance field.
3. On the same tab in the Connection section, enter MY_ODI_PR in the User field, and the actual password for this user in the Password field.
4. On the JDBC tab of the Data Server panel, select Oracle JDBC Driver in the JDBC Driver pull-down. Then enter the JDBC URL in the JDBC URL field, which might look like this: jdbc:oracle:thin:@localhost:1521:orcl
5. From the main menu of ODI Studio, select File->Save to save the data server you just defined.
6. In the top-left corner of the panel, click the Test Connection button to verify connection.
7. On the Topology tab, under the Physical Architecture->Technologies->Oracle node, right-click po_target, and select New Physical Schema.
8. On the Definition tab of the po_target.Schema panel, in Schema(Schema) select MY_ODI_PR from the drop-down list. Select the same in Schema(Work Schema).
9. From the main menu of ODI Studio, select File->Save to save the physical schema.
The next step is to create a logical schema to bind with the physical schema just created.
10. On the Topology tab, expand the Logical Architecture->Technologies node, and right-click Oracle, then select New Logical Schema.
11. On the Definition tab of the Logical Schema panel, enter a Name; for example: POrders_tgt. From the drop-down list under Physical Schemas, select the physical schema created in these steps earlier: po_target.MY_ODI_PR.
12. From the main menu of ODI Studio, select File->Save to save the logical schema just defined.
Now you can create a model for the topology just defined.
13. Move on to the Designer tab of ODI Studio. Expand Models and right-click the POrders folder created in the steps provided in the previous section, then select New Model from the menu.
14. On the Definition tab of the Model panel, enter a name in the Name field; for example, PO_TGT. Also, choose Oracle in the Technology pull-down, and POrders_tgt in the Logical Schema pull-down
15. On the Reverse Engineer tab of the Model panel, click the Reverse Engineer button to launch a reverse-engineering process. The datastores to be reverse-engineered with this model is geography_dm, time_dm, and sales_fact. They should appear under the POrders->PO_TGT node within the Models panel, once the reverse-engineering is completed.
You are almost there.
Creating and Running the Mapping
Now it's time to return to the MY_ODI_PR project you created following the steps in the Creating a New Project in ODI 12c section earlier in this article.
1. In ODI Studio, on the Designer tab, expand the Projects->MY_ODI_PR->First Folder node, and right-click Mappings, then select New Mapping from the menu.
2. In the New Mapping dialog, enter the mapping name such as Mapping_1, and click OK.
3. On the Designer tab, expand the Models->POrders->JSON_POs node. Then, drag the following objects into the Mapping_1 panel: ADDRESS, SHIPPINGINSTRUCTIONS, PORDERS, LINEITEMS, and PART.
4. From the Components palette on the right, drag and drop Join into the Mapping_1 panel.
5. In the Mapping_1 panel, connect the datastores output connector points to the join input connector point, so that each datastore is connected to the join with an arrow, as shown in the figure below:
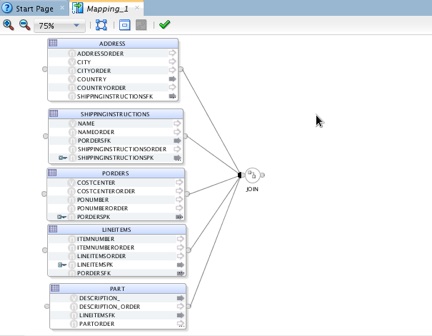
Figure 14: Modeling ODI objects in a mapping.
6. In the Mapping_1 panel, select the join, and go down to the JOIN-Properties window. If you can find it, select Windows->Properties from the ODI Studio main menu.
7. On the Condition tab of the JOIN-Properties window, specify the join condition:
ADDRESS.SHIPPINGINSTRUCTIONSFK =
SHIPPINGINSTRUCTIONS.SHIPPINGINSTRUCTIONSPK AND
SHIPPINGINSTRUCTIONS.PORDERSFK = PORDERS.PORDERSPK AND LINEITEMS.PORDERSFK = PORDERS.PORDERSPK AND PART.LINEITEMSFK =
LINEITEMS.LINEITEMSPK
8. On the Designer tab, expand the Models->POrders->PO_TGT node. Then, drag GEOGRAPHY_DM, TIME_DM, SALES_FACT into the Mapping_1 panel.
9. From the Components palette, drag and drop two Lookup objects into the mapping.
10. In the Mapping_1 panel, connect the objects so that you have the following design:
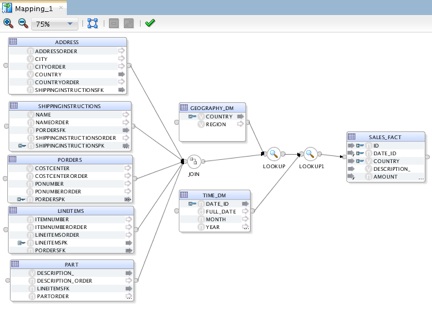
Figure 15: Final Design.

For the first lookup set up the following lookup condition:
GEOGRAPHY_DM.COUNTRY=ADDRESS.COUNTRY
For the second one:
TIME_DM.DATE_ID=TO_NUMBER(SUBSTR(PORDERS.reference,
INSTR(PORDERS.reference, '-')+1 ,8))
The expressions for the sales_fact attributes should be set as follows:
ID: LINEITEMS.LINEITEMSPK
DATE_ID: TO_NUMBER(SUBSTR(PORDERS.reference, INSTR(PORDERS.reference, '-')+1 ,8))
COUNTRY: ADDRESS.COUNTRY
DESCRIPTION_: PART.DESCRIPTION_
AMOUNT: PART.unitprice*LINEITEMS.quantity
11. In the main menu of ODI Studio, select Run->Run... to execute the mapping, which should start the process of populating the fact table with the data.
12. To verify the data was exported correctly, right-click SALES_FACT in the mapping and select Number of Rows... You should see something like 44807 as a result.
As you can see, using ODI, you can not only create a dimensional environment within an Oracle database but also load it with data. Since such an environment is still a collection of database objects, you can access it with direct SQL queries if necessary.
You can explore the underlying database schema in Oracle SQL Developer or in another SQL tool of choice, as illustrated in a figure below:
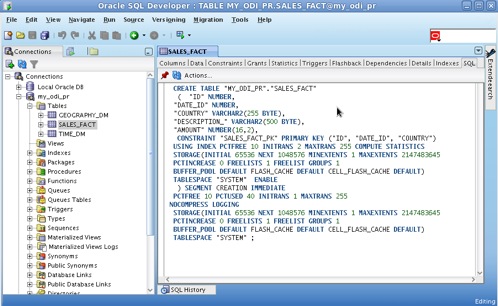
Figure 16: Using SQL Developer to check out the DDL statement used to create the SALES_FACT table.
And of course, you can issue an SQL query against the SALES_FACT table, just like against any other regular database table. The query in the following example counts the number of orders issued in August:
SELECT count(*) FROM SALES_FACT WHERE EXTRACT(month FROM TO_DATE(DATE_ID , 'YYYYMMDD')) = 8;
COUNT(*)
--------------
3754
You can be more specific, using more expressions in the WHERE clause and thus narrowing down your query:
SELECT count(*) FROM SALES_FACT WHERE EXTRACT(month FROM TO_DATE(DATE_ID , 'YYYYMMDD')) = 8 AND country = 'Germany';
COUNT(*)
--------------
21
It is important to note, however, that you don't have to switch from ODI Studio when you need to query your dimensional structure. You can reproduce almost any SQL query using ODI. For that, ODI provides components that you can use between sources and targets in a mapping to manipulate data. In ODI Studio, these components can be found on the component palette in the mapping diagram, allowing you to implement aggregation, pivot/unpivot, as well as many other data manipulation operations.
Conclusion
As you learned in this article, before you begin to design the dimensional model of a business, you must clearly define a set of questions you want to get answered through analyzing your business data. Once you have those questions defined, you can proceed to organizing the data in a way convenient for dimensional analysis. This is where tools like Oracle Data Integrator 12c come in very handy. As for data sources, Oracle Data Integrator 12c can integrate (process and transform) data from various heterogeneous data sources – not necessary hosted in an Oracle database.
See Also
About the Author
Yuli Vasiliev (@"Yuli Vasiliev") is a software developer, freelance author, and consultant currently specializing in open source development, Java technologies, business intelligence (BI), databases, service-oriented architecture (SOA), and more recently virtualization. He is the author of a series of books on the Oracle technology, including Oracle Business Intelligence: An introduction to Business Analysis and Reporting (Packt) and PHP Oracle Web Development: Data processing, Security, Caching, XML, Web Services, and Ajax (Packt).