by Johan Louwers
Learn how to test your application's behavior when your network is not providing optimal service, how to test whether your network monitoring scripts work, and how to simulate strange network behavior in a contained, controlled manner and without impacting the network adversely.
Networking has and will always be an important part of IT solutions. You can build the most beautiful solutions, but if you are unable to expose them to the enterprise, they will not be of any use to users. With the trend of enterprises moving to the cloud and the adoption of microservices-based solutions, the network becomes even more important.
The area in which administrators, in general, lack available tools is monitoring the network in depth. Most enterprises implement monitoring to check the status of network equipment, for example, routers and switches. Also it is quite common to use monitoring scripts to check if a ping command sent to a server returns. However, checking whether a ping command comes back within a given amount of time is beyond the capability of many IT departments, unfortunately.
Doing deeper netflow analysis, routing analysis, and end-user-perspective analysis is something that should be common practice; however, that is not commonly seen within most enterprises. In the cases where it is done, it is commonly done by the network department in a "silo" manner where the data is not shared (by default) with other departments who could receive a huge benefit from it.
Using Oracle Enterprise Manager
In general, solutions such as Oracle Enterprise Manager (and other solutions) are moving away from monitoring an instance or single component as a target and, instead, the entire end-to-end landscape is becoming the monitoring target. This means that monitoring from an end-user perspective is becoming more adopted, for example, by using Oracle Real User Experience Insight and monitoring network connections between zones.
For example, monitoring the network speed between two components—the application server and the database server—is becoming (almost) a standard in enterprises that realize network monitoring deserves more attention than it is getting.
For monitoring the network between an Oracle WebLogic application server (or any other application server) and an instance of Oracle Database you can use, as an example, Oracle Enterprise Manager and remote beacons. Remote beacons can be deployed across the network and execute a number of custom checks. Remote beacons are a standard component of Oracle Enterprise Manager; however, they are commonly overlooked even though they are a powerful tool especially for monitoring network connectivity and speed between all kinds of components (targets).
How to Develop, Deploy, and Test Remote Beacons and Scripts
The question of how to develop and deploy remote beacons and possibly the custom-coded checks you want them to execute is "simply" answered by reading the Oracle Enterprise Manager documentation. The trickier part is how you test them.
Without too much effort, you can develop checks that monitor the results of TNSPING, ping, or whatever network-related command you would like to monitor. However, testing the checks becomes a bit more difficult. Slowing down your network to test whether your script is doing the right thing and the alert is triggered in the right manner under the right condition can be a daunting task; you might not want to play with switches or flood the network with bogus traffic.
This is where the netem Linux kernel module comes into play. The module needs to be compiled with your kernel, and then you can use it to emulate conditions on the network on a Linux machine. The Linux operating system will interpret the emulated conditions as a true network condition while the conditions are, in fact, emulated behavior controlled by the netem module.
Using the netem Kernel Module
When you need to test certain conditions on your network, for example, slow network response, you do not want to do this by playing with switches and routers in your network. You most likely want to do this in a contained and controlled manner. Using the netem kernel module will help enormously with this.
If you use lsmod to check for netem, you most likely will find that is it not loaded directly.
[root@testbox09 ~]# lsmod | grep netem[root@testbox09 ~]#
However, you can load it using the command below as an example; this will add a delay 97 ms on all traffic on eth0 by using netem.
[root@testbox09 ~]# tc qdisc add dev eth0 root netem delay 97ms
[root@testbox09 ~]#
The command above means that if you used to have a ping time between about 13 ms and 16 ms when pinging google.com, it will now take between 110 ms and 113 ms.
[root@testbox09 ~]# ping google.com
PING google.com (74.125.136.139) 56(84) bytes of data.
64 bytes from ea-in-f139.1e100.net (74.125.136.139): icmp_seq=1 ttl=49 time=112 ms
64 bytes from ea-in-f139.1e100.net (74.125.136.139): icmp_seq=2 ttl=49 time=112 ms
64 bytes from ea-in-f139.1e100.net (74.125.136.139): icmp_seq=3 ttl=49 time=110 ms
64 bytes from ea-in-f139.1e100.net (74.125.136.139): icmp_seq=4 ttl=49 time=111 ms
64 bytes from ea-in-f139.1e100.net (74.125.136.139): icmp_seq=5 ttl=49 time=113 ms
^C
--- google.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 9006ms
rtt min/avg/max/mdev = 110.690/112.165/113.122/0.885 ms
[root@testbox09 ~]#
Now, in the example above, we pinged google.com, but you can see that you can easily use this command to add a delay on eth0 to test an Oracle Enterprise Manager remote beacon (or any other alerting script that is used). When you need to check which rules you have applied, you can use the command below to see a list of all rules that are active:
[root@testbox09 ~]# tc -s qdisc
qdisc netem 8001: dev eth0 root refcnt 2 limit 1000 delay 97.0ms
Sent 7982 bytes 62 pkt (dropped 0, overlimits 0 requeues 0)
backlog 118b 1p requeues 0
[root@testbox09 ~]#
To ensure your machine is acting normally and things are working as expected, you need to remove the rule. As we just have seen, we have one rule active.
Here are the commands for removing the rule and checking if it has been removed:
[root@testbox09 ~]# tc qdisc del dev eth0 root netem
[root@testbox09 ~]#
[root@testbox09 ~]# tc -s qdisc
qdisc pfifo_fast 0: dev eth0 root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 734 bytes 5 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
[root@testbox09 ~]#
And here is the command to check whether things are back to normal again:
[root@testbox09 ~]# ping google.com
PING google.com (74.125.136.102) 56(84) bytes of data.
64 bytes from ea-in-f102.1e100.net (74.125.136.102): icmp_seq=1 ttl=49 time=13.7 ms
64 bytes from ea-in-f102.1e100.net (74.125.136.102): icmp_seq=2 ttl=49 time=13.6 ms
64 bytes from ea-in-f102.1e100.net (74.125.136.102): icmp_seq=3 ttl=49 time=14.2 ms
^C
--- google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2339ms
rtt min/avg/max/mdev = 13.692/13.905/14.284/0.285 ms
[root@testbox09 ~]#
How Does netem Work?
As you can see, we used something named netem, which is shown by lsmod as sch_netem. However, we also used tc qdisc, so you might be wondering how this all ties together.
If you read the netem man page, you'll see the following: "NetEm is an enhancement of the Linux traffic control facilities that allow to add delay, packet loss, duplication and more other characteristics to packets outgoing from a selected network interface. NetEm is built using the existing Quality Of Service (QOS) and Differentiated Services (diffserv) facilities in the Linux kernel."
This means that netem is an enhancement component of Linux traffic control to simulate specific behavior in IP traffic.
Figure 1 shows how the entire "stack" is being used to allow a process to communicate to an address somewhere on the network:
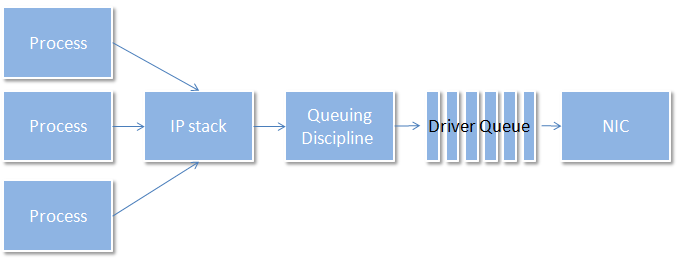
Figure 1. The stack that allows a process to communicate to a network address
The command we used, tc, configures traffic control in the Linux kernel. As you have noticed, the command was tc qdisc add dev eth0 root netem delay 97ms, which roughly translates to the following:
traffic control queuing disciple, add on device eth0, as the user root, a network emulator rule for a delay of 97 ms
By using this command, you have a netem delay rule that influences the queuing disciple that will hold traffic for 97 ms before releasing it to the driver queue of the associated NIC. This also means that the rest of your system is completely unaware of any changes to the system, because the only part that has knowledge of this netem rule is the queuing disciple. No applications will ever know this is simulated behavior.
Doing More with netem
As you look at the netem (tc-netem) man page, you will notice that the following is stated: "add delay, packet loss, duplication and more." In the example above, we saw how to add delay.
If you read the netem man page in more detail, you will find that next to the delay option we used in the example above, many other options are available to simulate the behavior of your network. Other available options include the following:
limit packetsdistributionloss randomloss stateloss gemodelecncorruptduplicatereorderrate
All of the above will provide you with more options to simulate strange network behavior and test how your application, or testing scripts, will cope without the need to interfere with the actual network itself.
As an example, you can state a loss of 50 percent of the packages going out by using the following command. One small piece of advice, though, is to remember that if you use a network connection to connect to the machine and you use the same NIC for this, your own connection will also suffer from this behavior, meaning you will also be hit by the 50 percent package loss in your SSH session.
[root@testbox09 ~]# tc qdisc add dev eth0 root netem loss 50%
[root@testbox09 ~]#
[root@testbox09 ~]# ping google.com
PING google.com (216.58.217.46) 56(84) bytes of data.
64 bytes from 216.58.217.46: icmp_seq=6 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=7 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=18 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=20 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=21 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=24 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=25 ttl=48 time=116 ms
64 bytes from 216.58.217.46: icmp_seq=27 ttl=48 time=116 ms
^C
--- google.com ping statistics ---
28 packets transmitted, 8 received, 71% packet loss, time 36813ms
rtt min/avg/max/mdev = 116.300/116.444/116.530/0.251 ms
[root@testbox09 ~]#
Conclusion
Testing how your application behaves when your network is not providing optimal service, testing how your network monitoring scripts work, and simulating strange network behavior all become much easier when you use netem, and using netem lowers the risk of conducting such tests.
Testing application behavior under strange network situations, ensuring you have the right monitoring scripts in place, and ensuring the scripts are tested in the right way can be vital for delivering a service to end users. Investing time in using netem and including it in your toolset will be a huge advantage.
See Also
netem man page
About the Author
Johan Louwers is an Oracle ACE Director and leads the Capgemini Global Oracle Architect Office in his role as Global Chief Architect for Oracle Technology within the Capgemini infrastructure division.
Follow us:
Blog | Facebook | Twitter | YouTube