Recovery Terminates on Standby After a PITR of a PDB on Primary Database in Oracle 12c
by Shivananda Rao
This article is for DBAs who have a setup/environment on Oracle Database 12c with a Pluggable Database (PDB) plugged into the Container database. This is how to overcome a scenario where the recovery (MRP) terminates on the physical standby database after a Point In Time Recovery (PITR) of a PDB is performed on the Primary database. This is one of my favorite features I use typically to overcome such an issue.
As of Oracle 12c, Point In Time Recovery (PITR) is possible at Container Database (CDB) level and at Pluggable Database (PDB) level making things simpler. This article discusses how the physical standby database is affected after a PITR of a Pluggable Database is performed on the Primary database. A PITR is an incomplete recovery process; since the recovery is performed until a specific time at the Primary, there is data loss.
Oracle ASM has some great capabilities and advantages such as ease of management, high performance, and low overhead. It also solves many storage challenges, because it allows removing/adding disks online and it will automatically rebalance the data across the disks to avoid a bottleneck on a specific disk; thus, it provides the best performance.
The PITR requires opening the Primary database with the RESETLOGS option and starting a new incarnation of the database.
This concept of the PITR holds good for the PDB as well alongside the CDB in 12c. But let's say, we have a physical standby database configured for the primary database which has the same PDBs plugged into it. Any thoughts on what exactly happens to the physical standby database when a PITR is performed on a PDB of a primary database?
In pre-12c versions, before the invention of Multitenant databases, a PITR of the primary database affected the entire database and would require flashing back the standby to match the Primary (if possible) or lead to the re-creation of the standby if flashback was not enabled and the standby had applied redo past the SCN of the PITR.
In 12c, though, the standby database is built at CDB level, meaning that redo generation at the Primary and redo apply at the standby covers all PDBs in the CDB. This means that a PITR of a PDB on the primary database leads to the termination of the recovery (Managed Recovery Process) on the physical standby database and the errors (ORA-39874 and ORA-39873) would be reported in the alert log of the standby database.

So, how do you overcome such a scenario? I've outlined the steps to get the physical standby in sync with its primary database after a PITR was performed.
Environment
The environment comprises a 2-node RAC Primary database (SRPRIM) with PDB1 as a pluggable database plugged into it and a corresponding 2-node RAC Physical Standby database (srpstb) with the same PDB1 as a pluggable database plugged in. There has been no Data Guard Broker configured for this setup although the same procedure works fine when the Broker is configured. Point-In-Time Recovery (PITR) is also performed on PDB1 at the primary site and this is not outlined in this article. You can refer to the Database Backup and Recovery User's Guide for more details.
From the alert log file of the standby database (the instance on which managed recovery process was running), the following error message is reported indicating the termination of MRP and the recovery of the problematic PDB with the corresponding checkpoint SCN.
On the Primary, a PITR was performed on PDB1 at SCN 1957233 and the same is indicated in the alert log of the standby database.
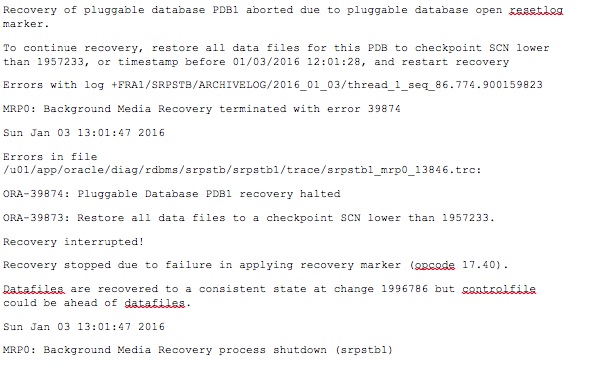
Let's get the incarnation details of the PDB1 on the primary database.
It can been seen that the INCARNATION SCN for the CURRENT status of PDB1 is 1957233 which means that a PITR was performed on this pluggable database at SCN 1957233 and was opened with resetlogs at SCN 1996783. Now, in order to start the recovery on the standby database and get it in sync with the primary, we need to follow the following steps.
Step 1: Mount the standby database and have the problematic pluggable database in a closed state.
Step 2: Identify the backup which is equal or less than 1957233 SCN.
We know the SCN at which the PDB was recovered on primary, so identify the backup which is equal or less than 1957233 SCN. If the backups are being taken from the standby, then the standby will automatically identify the corresponding backup pieces. If not, then identify the backup pieces on the primary and transfer it to the standby site. In this example, the backup is being taken from the primary database. Hence the required backup piece (/u02/bkp/SRPRIM_inc0_20160103_0eqqekl6_1_1.bak) is identified and shipped to the standby site. From the primary site:
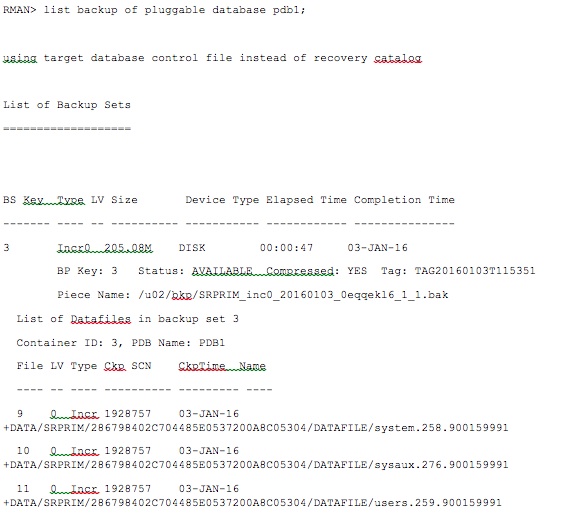
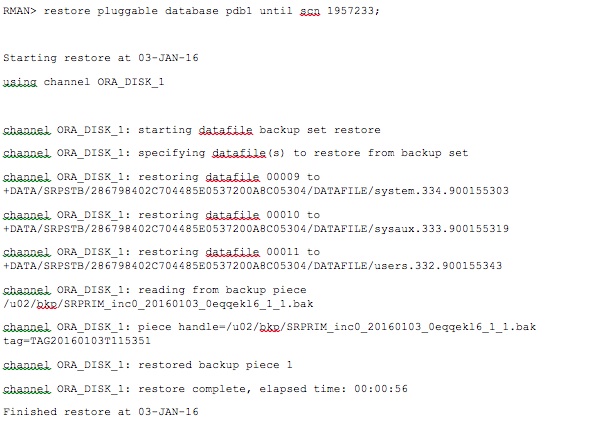
Step 3: Restore the pluggable database PDB1 on the standby site until the SCN (1957233) at which the PITR was performed for this PDB on the primary.
This SCN can be obtained from the alert log file of the standby at which the error ORA-39873 was reported. If the backup piece identified in "Step 2" is copied over to a different location on the standby site, then this backup piece needs to be catalogued with the standby database before restoring.
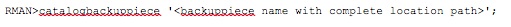
In my case, I have this file copied over to the same location on the standby site (/u02/bkp/) and hence I'm not cataloging the backuppiece. Moving on with the restore, the pluggable database is being restored until SCN 1957233 on the standby database.
Step 4: After restoring is completed, let's start the managed recovery process (MRP) on the standby database.
Data Guard will continue recovery of this PDB as well as all other PDBs in the Standby CDB as normal.
RMAN> alter database recover managed standby database disconnect;
Statement processed
Check the recovery status on the standby database:
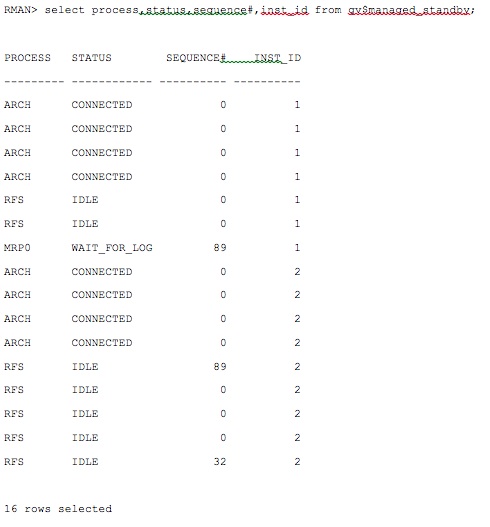
It's clear that now MRP is running and waiting for the next log sequence from the primary database. If Active Data Guard license is available, then stop the recovery, open the standby and the corresponding PDBs in READ ONLY mode and restart the recovery again.
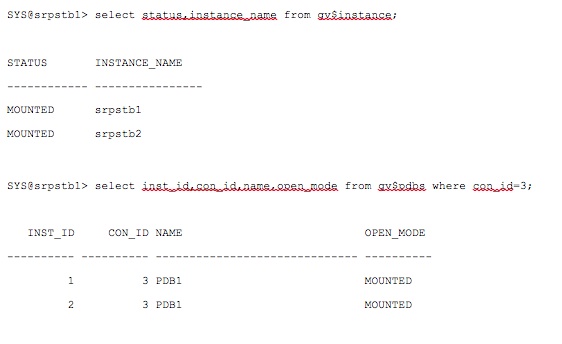
Step 5: Let's check the incarnation details of the PDB1 PDB on the standby database. It should be the same as that on the Primary.
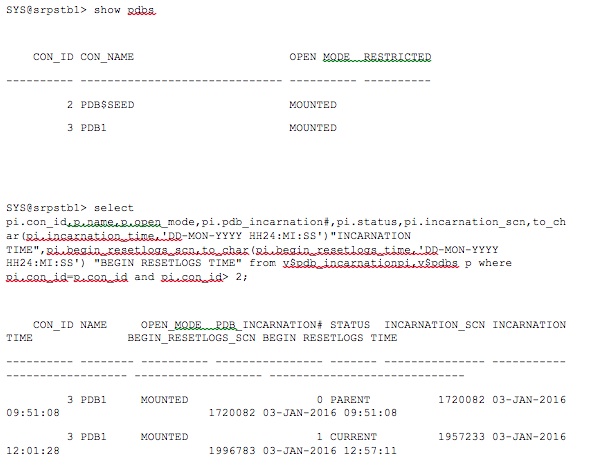
As shown above, the standby PDB is now on the same incarnation as the Primary PDB. Alternatively, another quick option would be to flashback the standby database to the SCN that is reported in the alert log of the standby instance, provided FLASHBACK was enabled on the standby. This process removes the need of identifying the right backup, copying them from the primary site to the standby site and then restoring them at the standby site.
Here are the steps that need to be followed if FLAHSBACK is enabled for the standby database.
- Identify the SCN at which the PDB PITR was performed on the primary. As said earlier, this can be obtained from the alert log of the standby database at which ORA-39873 was reported.
- Flashback the standby CDB to the SCN that is determined above.
SQL> flashback database to SCN 1957233;
3. Start the recovery on the standby and monitor the progress.
Conclusion:
A PITR is always performed on a primary database and not on the standby database. This is a good feature in 12c where a PITR of one PDB does not impact the CDB to which it is plugged in or to the other PDBs that are plugged in under the same CDB, but the standby CDB recovery is terminated completely and goes out of sync until it recovers the PDB through the resetlogs using one of the two methods discussed in this paper.
About the Author
Shivananda Rao is an Oracle ACE Associate and working as a Senior Oracle DBA. He has good knowledge on Oracle technologies specifically with High Availability, Disaster Recovery, Upgrades and RMAN. He has been actively participating in the OTN forum and maintains Oracle technical blog (www.shivanandarao-oracle.com) which has more than 50 articles published by him. He has an expertise of working on Dataguard and RMAN issues with much concentrated on High Availability topics.