This two-part article by Oracle ACE Director Antonis Antoniou compares the differences in fault handling options between 11g and 12c and explores the new error handling and recovery features introduced in Oracle BPM 12c from both a developer’s angle (part 1) and an administrator’s perspective (part 2).
By Oracle ACE Director Antonis Antoniou 
Introduction
The ability to handle exceptions and recover from errors is fundamental to implementing reliable and robust business processes and enterprise systems.
There might be cases, though, when an unexpected problem occurs during the runtime lifecycle of a process that will cause your process to fail. This could be the result of a connectivity loss, a failure in a database connection, a selection failure, or a failure during an invoke activity. These types of errors, referred to as systems errors, arise directly from the underlying software or hardware infrastructure where the BPMN Service Engine is running.
There might be cases when business faults occur. These are application-specific faults that are generated when there is a problem with the information being processed (e.g., a stock control and inventory service throwing an error when a stock item is not found). Business faults are a more “controlled” fault type since you are aware of its plausible appearance; it can occur only if your application executes a THROW activity or your invoke activity receives a fault message response.
However, despite their essentialness, error handling and recovery are often overlooked in Business Process Management (BPM) projects. Analysts tend to model exception handling (mostly system or rare business faults) in the BPMN, making process design very complex, and very difficult to read and follow—resulting in skyrocketing maintenance efforts.
The new release of Oracle BPM Suite 12c introduced some really nice new error handling and recovery features. And even though I am tempted to just put on my developer’s hat, I cannot ignore the importance of the fundamental improvements Oracle has made in error recovery, from an operations and management perspective.
This two-part article will compare the differences in fault handling options between 11g and 12c and will explore the new error handling and recovery features introduced in Oracle BPM 12c from both a developer’s angle (part 1) and an administrator’s perspective (part 2).
Main
Force Commit After Execution
One of the new developer-oriented error handling and recovery features in Oracle BPM 12c is the “Force commit after execution” option (see Figure 1, below). This option configures activities, events and gateways to explicitly force BPM runtime to add a checkpoint in the dehydration store, committing the state of the BPM instance after their execution.

Figure 1
This important new feature lets developers explicitly force dehydration during process execution to avoid re-executing non-idempotent activities in case an error forces the transaction to be rolled back.
Let’s take, for example, the loan initiation process. A customer requests a loan and the system exports the loan application into an xml file before persisting the loan application data into an operational database (see Figure 2).

Figure 2
If you run the above scenario, you will notice that an xml file is created with the details of the loan application (see Figure 3) and that the loan details have been inserted into the Loans database table (see Figure 4).

Figure 3
 Figure 4
Figure 4
For the purposes of raising an exception and demoing this feature, the “Create Application” service uses a static loan id when inserting the loan details into the “Loans” table. If you run a new instance of the loan process, a new xml file should be created (see Figure 5), and the process should fault on the “Create Application” service call since it will try to insert a new loan using an existing primary key (see Figure 6).

Figure 5

Figure 6
Since we already know what the problem is—a primary key constraint violation—before recovering the instance, we have to delete the existing loan record in the “Loans” table. What’s more interesting is that, when you recover the instance, you should notice that a second file for this specific instance is being created (see Figure 7).

Figure 7
To avoid re-executing the “Write Loan To File” service in case of an exception, you will have to enable the “Force commit after execution” feature on that service task (see Figure 1). Running the same process with the “Force commit after execution” feature enabled for the “Write Loan To File” service task should result in only one execution of the “Write Loan To File” service in case of an exception and recovery, and thus only one file will be created.
In BPM 11g, to achieve such functionality you had to “trick” the BPM engine by using a timer catch event at your various checkpoints, setting the timer duration to more than one second (setting the timer to 2 seconds is sufficient).
To be able to provide an objective comparison of the two approaches, in terms both of performance and execution, I have created the same process flow using the same service calls in a new BPM project; I’ve used a timer catch event right after the “Write Loan To File” service task to force the BPM engine to dehydrate the state of the running instance (see Figure 8).
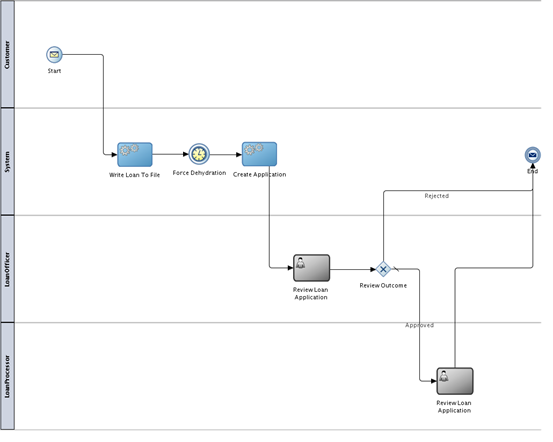 Figure 8
Figure 8
The results were very interesting. The first process, with the “Force commit after execution” feature enabled, took 1 second to complete (see Figure 9).

Figure 9
The second process, with the timer catch event used to force an instance state dehydration, took 2 seconds to complete (see Figure 10).

Figure 10
Even though we can see statistical proof of a performance improvement, the dehydration performance between 11g and 12c is the same. Running the timer catch process in 12c yields exactly the same performance results.
Using a timer catch event, the engine requires a setup of 2 seconds to initiate and execute a dehydration process. Setting the timer to anything less than that will not snapshot your instance. Therefore, we can assume that there is a triggering threshold for sparking the dehydration process and that the total dehydration processing time for a timer catch event is calculated as follows:

DPt = Dehydration Processing Time in seconds
With the current metrics we realize that there is a triggering overhead of 1 second associated with a timer catch event when used to force dehydration.
The new “Force commit after execution” feature in 12c is clearly a much better approach, offering an easier and declarative approach for defining your dehydration checkpoints and keeping a clean modeling process canvas.
OK, Skip, and Back Error Recovery
BPM 12c also introduces the “Skip” and “Back” actions that you can define on a flow object to choose whether to re-run a faulted flow object or just move to the next flow object as defined in the process flow.
You can set a new pre-defined variable named “action” to either “send,” “back” or “skip” using either the known data associations (see Figure 11) or using Groovy scripting, another great new feature introduced in BPM 12c.
 **
**
Figure 11**
The default action value is “send” and can be thought of as a try-catch block where the activity that is in the try block and the error handler is in the catch block. In case of an exception, the process flow that was running when the exception occurred is cancelled and the process instance moves to the next flow object in the exception handler.
When the action variable has been configured with a “back” value, and an exception occurs, the process instance will move back to the flow object where the exception occurred and will attempt to re-execute the faulted flow object. EXERCISE CAUTION WITH THIS OPTION: there is a high risk that you will end up in an infinite loop of re-executing the faulted flow object.
The third option is “skip.” As its name implies, in case of an exception, the process instance will move on to the next activity in the process flow.
So let’s see this new feature in practice, using the loan process created in the “Force Commit After Execution” section above.
For the purpose of demonstrating this new feature, I have created a new service called “CheckCreditProcess” to simulate a credit checking service (see Figure 12). The service is pretty simple. If the supplied customer id is equal to 3, the service will throw a CustomerNotFound fault; if the customer id is equal to 4, the service will throw an InvalidSSN fault; otherwise, the service will create an entry into the “CREDIT_CHECK” table to record the credit check transaction and return a “Valid” status.

Figure 12
Further, I have updated my loan process by adding a new service task between the “Write Loan To File” and “Create Application” service tasks to call the newly created “Check Credit” service (see Figure 13).

Figure 13
To handle the exceptions that might occur during the invocation of the “Check Credit” service, I have used two event subprocesses (see Figure 14), changing their implementation types from the default “Message” to “Error” and configuring the implementation to listen for “CustomerNotFoundFault” (see Figure 15) and “InvalidSSNFault” (see Figure 16) faults, respectively.

Figure 14

Figure 15

Figure 16
Using a script task, I have defined the action value to “back” for the “CustomerNotFoundFault” (see Figure 17), since this a critical type of error, and “skip” for the “InvalidSSNFault” (see Figure 18) fault event subprocesses, since the latter is a minor fault type and we don’t want to re-execute the “Check Credit” service.

Figure 17

Figure 18
And, to make sure I don’t get caught up in an infinite loop (in the “back” scenario but also in the “skip” scenario to ensure my next activity, which is the “Create Application,” doesn’t fault due to an invalid customer id), I am updating the customer id to a valid customer id. Please note that, at runtime, the action is taken immediately on setting the action.
If you initiate a new loan process with the customer id set to 3, you will notice that the “Check Credit” service failed with a “CustomerNotFoundFault”; the error event subprocess caught the business exception and the BPM engine automatically recovered the instance by re-executing the “Check Credit” service (see Figure 19), which succeeded the second time (since the customer id was updated).

Figure 19
If you initiate another loan process instance, this time with the customer id set to 4, you will notice that the “Check Credit” service failed with an “InvalidSSNFault.” The error event subprocess caught the business exception, and the BPM engine automatically recovered the instance by skipping the “Check Credit” service and moving on to the next activity—the “CreateLoanProcess” service task (see Figure 20).

Figure 20
New Fault Policy Editor in JDeveloper
Oracle SOA Suite provides us with a Fault Management Framework, a generic framework that uses policies defined in XML files for handling faults. The Fault Management Framework is nothing new; it has existed since 11g and intercepts a fault before the standard fault handler. Once the Fault Management Framework catches a fault, the framework attempts to perform a user-specified action defined in the fault policy XML file. With this very robust framework, policies can be reused across composites, components and applications to catch and recover from both runtime and business faults.
In 11g, you could create fault policies only in source mode, because there wasn’t a graphical editor available. With the new release of BPM Suite 12c, an entirely new visual editor has been added into JDeveloper for creating fault policies (see Figure 21).

Figure 21
Again, to demonstrate this new feature I will be using the loan process. Since I will be using the fault policies of the Fault Management Framework to handle exceptions in my loan process, I have deleted the two error event sub-processes (see Figure 14).
Every time you invoke the “Fault Policy Document” editor you are basically creating a new policy XML file with the default policy file being the “fault-policies.xml” file created under the SOA folder. Each time you create a new policy file, JDeveloper will append a sequence number to the policy file name (e.g., fault-policies-2.xml).
Each policy document can contain multiple policies (e.g., a fault policy for the CustomerNotFound fault and a policy for the InvalidSSN fault (see Figure 22)). Each fault policy can contain multiple fault handlers, and each fault handler can have multiple actions. And for fault handler, you can define various alerts and assign them to your actions.

Figure 22
Faults are categorized under the Fault Hander section into “System Faults”—binding faults, mediator faults and remote faults—and “Service Faults”—a list of all the faults defined per WSDL that your composite uses, such as the “InvalidSSN” and “CustomerNotFound” faults (see Figure 23).

Figure 23
For each Fault Handler you can select a default action from a list of predefined actions (see Figure 24). The action here allows you to define and control what to do in case of an exception. You can, for example, abort and terminate the instance, request human intervention via the Oracle Enterprise Manager (OEM) Fusion Middleware Control, replace the faulted scope, re-throw the fault, retry executing the faulted activity (by which you specify the number of re-execution times, a delay in seconds between the retries, option to increase the interval with an exponential back off, and a retry success and retry failure action), execute a custom Java class, invoke a web service, enqueue a rejected message to a queue as a JMS message, or store a rejected message in a file. The last three actions, “Invoke WS,” “Enqueue” and “File Action” are new 12c action types.

Figure 24
Each Fault Handler can have multiple actions defined, meaning that you can execute any of the above actions whenever a fault occurs. Furthermore, via expression language, you can define an expression that will evaluate to a Boolean, so you can control when an action should fire. For example, the InvalidSSN fault contains two variables, a code and a description. If the error code is “ERROR-001,” terminate the instance. If the error code is “ERROR-002,” try to replay the faulted scope (see Figure 25). For all other error codes I will use human intervention.

Figure 25
For each fault handler you can define a set of alerts, which you can then map to your actions. Alerts is a new fault policy feature in 12c that currently supports three types of alerts: send an email alert in case of an exception; enqueue the fault to a JMS queue or publish it to a JMS topic; or write an alert to the server’s log.
Note: As with 11g, for your process to identity and use the Fault Management Framework and fault policies, you need to manually create the fault-bindings.xml file and register your fault policies (see Figure 26).

Figure 26
You must also manually assign your fault policy file and fault-binding file to the composite artifacts (see Figure 27).

Figure 27
When a new loan process is initiated using a customer id that will cause an InvalidSSN fault, the Fault Management Framework intercepts the fault and, based on the actions defined in the policy file, acts accordingly.
In my case, I have defined a human intervention, which means that, if a fault occurs, I will be presented via the OEM Fusion Middleware Control with a set of recovery actions, along with all variables defined in my faulted instance by which I can update a variable’s value before recovering the instance (see Figure 28).

Figure 28
Summary
BPM instances can get “stuck” for various reasons: a failure during an invoke operation; a selection failure; a business exception. Whether exceptions are external, are due to a transaction rollback, or are the result of design issues, they all look the same and end up with a process instance unable to proceed. The ability to handle exceptions and recover from such errors is truly fundamental and multidimensional, having business and not just technical considerations. Idempotency must be considered, as must the side effects of re-executing non-transactional activities. In this first part of a two-part series, we’ve seen the error handling and recovery enhancement improvements that the 12c release has brought to the developers’ world. In Part 2, we will explore 12c’s considerable and important new administration features and enhancements.
Resources
About the Author




Oracle ACE Director Antonis Antoniou is a Technical Director with eProseed. He is a Fusion Middleware Expert specializing in Enterprise 2.0, Business Process Management, and Service Oriented Architecture, and has earned certifications in Oracle Application Grid, Oracle WebCenter Portal, Oracle WebCenter Content, ADF, Oracle BPM and Oracle SOA. Antonis has extensive experience as a developer, coach, trainer and architect, and has served as project lead on multiple complex Oracle Fusion Middleware projects across Europe and the Middle East, spanning various industries. Antonis is an avid technology evangelist and a regular speaker at various Oracle conferences and events.