by Randal Sagrillo, Ken Kutzer, and Larry McIntosh
This article describes how Oracle Database In-Memory in Oracle Database 12c enables high-performance data analytics, explaining the workload types that can be accelerated and how the software interacts with infrastructure hardware. Part 2 specifically examines how Data Analytics Accelerator (DAX) units in Oracle's SPARC processors accelerate analytical queries that use Oracle Database In-Memory.
|
Introduction
Real-time analytics can help companies gain insight, set business goals, and drive competitive success. But processing queries against databases tuned for online transaction processing (OLTP) transactions yields slow response times that negatively impact users and delay transaction processing. Alternatively, some organizations use complex extract, transform, and load (ETL) procedures, culling data from existing financial, customer, logistics, and human resources databases to build separate business intelligence systems. While this limits performance degradation on OLTP systems, data in these systems lags the production system, preventing real-time decision making on the most current data.
Oracle Database In-Memory, an option introduced with Oracle Database 12_c_, accelerates analytics performance both on data warehouses and mixed workload systems. It is easily deployed in conjunction with existing Oracle Database 12c applications, supporting real-time analytical queries without the need for application changes and without the need for a separate, dedicated business intelligence system. By setting a few simple parameters and selecting performance-critical database objects to be loaded into memory, Oracle Database In-Memory can accelerate queries that typically scan and aggregate large amounts of data to reveal important patterns or trends.
| |
|

Oracle Optimized Solutions provide tested and proven best practices for how to run software products on Oracle systems. Learn more.
|
|
Table of Contents

Adopting Real-Time Analytics for Fast Business Decisions
This article highlights how easy it is to adopt Oracle Database In-Memory and support mixed workloads—OLTP transactions as well as analytical query and reporting—with extremely responsive performance for both workload types. It describes targeted use cases for Oracle Database In-Memory, discussing the kinds of analytic queries that see optimal levels of acceleration.
Oracle Database 12_c_ and Oracle Database In-Memory are available on a wide variety of system platforms. However, when it comes to deploying Oracle Database 12_c_ with the Oracle Database In-Memory option, architecture matters.
Oracle has taken an innovative Software in Silicon (SWiS) approach with its SPARC processor design, incorporating hardware acceleration and security features directly into the processor. In this approach, SPARC processors incorporate Data Analytics Accelerator (DAX) units that can dramatically improve the performance of analytic workloads, yielding performance results beyond what's possible on other processor architectures. (To learn about Software in Silicon and its features, see "Software in Silicon: What It Does and Why").
On-chip DAX units offload Oracle Database In-Memory query processing, speeding up analytic workloads while at the same time freeing processor cores to work on other computing tasks, such as OLTP transactions or other application processing. In testing of an example analytical query, execution time on Oracle's SPARC T7-2 server dropped from 109 seconds (without Oracle Database In-Memory) to just 2 seconds when the query was unchanged but the session was optimized using Oracle Database In-Memory and configured to take advantage of parallelize query processing on DAX units. (For details, see the "Optimizing for Performance" section of "Architecture Matters, Part 3: Next Steps—Optimizing for Database Performance, Security, and Availability.")
This article explores the underlying software technology of the Oracle Database In-Memory option and how it can enhance analytics on all platforms. A companion article (Part 2) explains Software in Silicon technology and how DAX units on Oracle's SPARC processors can speed up query processing to achieve real-time analytics.
What Is Oracle Database In-Memory?
A relational database (such as Oracle Database) stores data in memory in row-based data records. This row-based layout, which places data into contiguous memory locations, is very efficient for SQL record inserts, updates, and deletes typical of OLTP transactional workloads.
In contrast, an analytical query—such as "show me all sales greater than x in region y"—on row-formatted data must read through large data sets and parse through many rows in memory, skipping over unneeded elements to get to the data of interest (such as the "sales" and "region" entries for this sample query). The time it takes to scan in large data sets and reach the relevant data in the row is one reason why running analytical queries against a relational database can sometimes take hours or days, rather than seconds or minutes.
One method of speeding up analytics is to create indexes in the relational database, but this tactic has limitations. First, it can decrease OLTP performance—a subsequent insert, for example, must update all of the indexes. Second, business users might want to perform analysis that was not predicted, and because indexes might not be available to accelerate those queries, total system performance can suffer. Alternatively, organizations can funnel data into separate data warehouses using labor-intensive and time-consuming ETL procedures, but data in these systems can quickly become stale, requiring many continuous repetitions of the ETL process.
A pure in-memory database (that re-creates the database in a columnar rather than row-based format) might seem like the right answer for real-time business analytics. If the data is restructured into columns in memory, the pertinent data—such as all "sales" and "region" values—can then be accessed directly without the need to scan in other data (such as "customer," "store," and so on). However, many pure in-memory solutions require the entire database to be replicated in expensive DRAM, and some solutions also require significant application rewrites.
In contrast, Oracle Database In-Memory uses an innovative dual-format architecture (Figure 1) that can optimize performance of business analytics and transactional workloads within a single system—without doubling the requirements for memory capacity and without any application changes. It adds a new database memory structure, the In-Memory column store (IM column store), that is formatted for analytical queries and that complements the traditional row-based buffer cache used for fast OLTP transactions. The DBA populates the IM column store with just the database objects needed for analytics, not the entire data set. The IM column store also compresses data, further reducing the amount of memory needed for analytics with Oracle Database In-Memory.
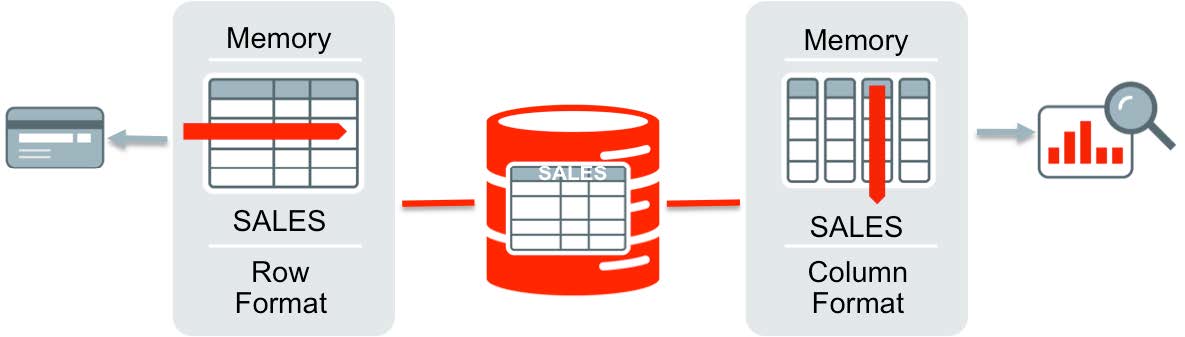
Figure 1: Oracle Database In-Memory uses a dual-format architecture.
As Figure 1 illustrates, an OLTP sales transaction can be easily inserted or retrieved as a row in the SALES table by accessing record elements in contiguous memory locations. For analytical queries, processing occurs against the IM column store instead. The Oracle Database optimizer is fully aware of the column format: it automatically routes analytical queries to the columnar data and OLTP operations to the row-based data, ensuring outstanding performance and complete data consistency for both workloads—without modifying the application. The result is optimal performance in both cases.
In developing Oracle Database In-Memory, Oracle set out to engineer a fast, effective—and yet nondisruptive—technology that can accelerate analytical queries using existing Oracle Database 12_c_ applications. A key goal was to make deployment trivial so DBAs could accelerate queries without rewriting and rebuilding software. Oracle Database In-Memory seamlessly integrates with existing Oracle Database applications, and it is completely compatible with the full suite of Oracle Database products and options, including Oracle Real Application Clusters (Oracle RAC), Oracle Active Data Guard, Oracle Recovery Manager (Oracle RMAN), and so forth.
Oracle offers other in-memory products, such as the following, but only Oracle Database In-Memory optimizes performance for both types of workloads on the same transactionally consistent relational database:
- Oracle TimesTen In-Memory Database. In contrast to the dual workload capabilities of Oracle Database In-Memory, this is a memory-optimized relational database that provides fast response times and high throughput for transactional applications. It is deployed in the application tier and requires the OLTP database to fit entirely in physical memory.
- Oracle In-Memory Applications for Oracle engineered systems. Many Oracle applications—including Oracle's JD Edwards EnterpriseOne, PeopleSoft, and Siebel applications; Oracle E-Business Suite; and Oracle Hyperion—are available as in-memory applications only for Oracle engineered systems. These applications are specialized software versions that take advantage of the extreme performance of Oracle engineered systems, transforming specific jobs that were once batch processes into real-time operations.
- Oracle Coherence. Oracle Coherence is a middleware layer that caches and reliably manages data objects in memory across a distributed grid of servers. It provides fault-tolerant data caching to simplify middleware scaling, allowing frequently used data to be stored and consumed at the application tier.
In contrast to these products, Oracle Database In-Memory supports mixed workloads efficiently, delivering superior response times for business analytics as well as OLTP transactions.
Configuring Oracle Database In-Memory
By default, Oracle Database In-Memory is disabled and no space is allocated for the IM column store. To enable it for the first time, a minimum of 100 MB must be allocated from the system global area (SGA) to the IM column store. For more information on determining the appropriate IM column store size, see the later section "Getting Started with Oracle Database In-Memory."
To configure the INMEMORY SIZE parameter, log in with administrator privileges and use an ALTER SYSTEM command. In the following example, the IM column store or space for columnar data will be set to 2 GB.
SQL> ALTER SYSTEM SET INMEMORY_SIZE=2G SCOPE=SPFILE;
Notes:
- For these changes to take effect, a database restart with an SPFILE is required.
- Setting
INMEMORY SIZE=0G will remove the IM column store space and effectively disable the Oracle Database In-Memory option after a restart is performed.
- The ALTER SYSTEM command can also be used to increase or decrease an existing IM column store:
- For Oracle Database 12_c_ Release 1 (12.1), a restart is required for an increase or decrease to take effect.
- For Oracle Database 12_c_ Release 2 (12.2), dynamic or live increases are supported; for a decrease operation, a restart is required for the change to take effect.
After Oracle Database In-Memory has been enabled, the administrator configures the database objects to populate in the IM column store. With buffer cache, the database automatically determines what data to populate based on recent workloads, predictions, and so forth. In contrast, with Oracle Database In-Memory, the administrator uses either an ALTER or CREATE statement to configure the objects to populate in the IM column store, the compression level to apply, and the population priority desired, as shown below:
SQL> ALTER TABLESPACE ts_data INMEMORY MEMCOMPRESS FOR QUERY HIGH PRIORITY CRITICAL;
SQL> ALTER TABLESPACE ts_data DEFAULT INMEMORY;
In the first example shown above, the compression level will be set to MEMCOMPRESS FOR QUERY HIGH and the population priority will be set to CRITICAL for all tables in tablespace ts_data. In the second example, the default compression level (MEMCOMPRESS FOR QUERY LOW) and the default population priority (NONE) will be used. In both cases, these commands are executed dynamically, while the database is operating and available for use. To remove an object from the IM column store, perhaps to make room for higher priority objects, use an ALTER command with the clause NOINMEMORY.
To learn more about compression levels, trade-offs, and hardware-based decompression, see the "In-Memory Compression" section of "Architecture Matters: Accelerate Analytics with Oracle Database In-Memory and Software in Silicon, Part 2." For more on population priorities, see Table 1 below.
At this stage, Oracle Database will now populate the IM column store with the configured database objects. During population, the database is fully available and queries will be satisfied from disk or buffer cache. Once the objects are available in the column store, the optimizer will automatically use the column-optimized objects when appropriate.
Notes:
- Upon a database restart, the population process must complete before optimized performance is available.
- Oracle Database 12.2 introduced a new feature called In-Memory FastStart that optimizes the population of database objects in the IM column store by storing in-memory compression units (IMCUs) directly on disk. Upon restart, these are read into the system avoiding the IMCU construction and compression process for a faster start up time.
Table 1. IM Column Store Populations Priority Levels
| Priority | Description |
| CRITICAL | Object is populated immediately after the database is opened |
| HIGH | Object is populated after all CRITICAL objects have been populated, if space remains available in the IM column store |
| MEDIUM | Object is populated after all CRITICAL and HIGH objects have been populated, if space remains available in the IM column store |
| LOW | Object is populated after all CRITICAL, HIGH, and MEDIUM objects have been populated, if space remains available in the IM column store |
| NONE | Objects populated only after they are scanned for the first time (default), if space is available in the IM column store |
While the administrator determines and configures which objects to place in the IM column store, with Oracle Database 12.2, the Automatic Data Optimization option has been enhanced to manage the IM column store by creating policies and automating actions based on those policies to implement an information lifecycle management (ILM) strategy for the IM column store. Automatic Data Optimization uses the Heat Map feature of Oracle Database, which tracks data-access patterns. These features enable DBAs to leverage automation to help manage the IM column store within the available capacity. Policies can include things such as evicting data that is minimally accessed, populating new data two days after creation, and so on to allow the IM column store contents to evolve as a database evolves with time.
Because pluggable databases (PDBs) in the Oracle Multitenant option to Oracle Database 12c share the same SGA and background processes of a common container database (CDB), multiple PDBs can also share the same IM column store, which conserves memory. For the IM column store on Oracle RAC nodes, it's recommended to set the INMEMORY_SIZE to the same value on each node. (If all table partitions cannot fit within an Oracle RAC node's IM column store, it's possible to allocate different partitions to stores on different nodes; see the Oracle Learning Library video "Oracle Database 12_c_ Demos: In-Memory Column Store Architecture Overview.") Additional information about configuring the IM column store is available in the white paper "Oracle Database In-Memory with Oracle Database 12_c_ Release 2" or in the Oracle Database Administrator's Guide in the section "Using the In-Memory Column Store."
What Makes In-Memory Queries Fast?
Oracle Database In-Memory implements four key processing enhancements to accelerate analytics:
- Compressed columnar storage
- Fast sequential memory scanning
- In-memory storage indexes
- In-memory optimized joins and aggregation
Described below, these capabilities contribute to overall faster analytic query and reporting speeds.
Compressed Columnar Storage
Because the IM column store enables sequential memory accesses, queries can rapidly scan needed data (much faster than nonsequential memory accesses across row-formatted data). Data is also typically compressed as it is placed into the IM column store, conserving space and reducing data-transfer sizes, resulting in more-effective use of the available memory bandwidth. Oracle provides tools (described later) that can help estimate compression ratios for database objects and determine the optimal size of the IM column store.
Several compression algorithms are available to optimize for query performance versus compression efficiency. The default compression setting (MEMCOMPRESS FOR QUERY LOW) optimizes for superior query performance across all system types and uses dictionary encoding, run-length encoding, and bit-packing compression techniques. The setting MEMCOMPRESS FOR CAPACITY HIGH is the most memory-efficient, while providing reasonable query performance. For specifics about compression settings and their trade-offs, see "Using the In-Memory Column Store" in the Oracle Database Administrator's Guide.
High-Performance Memory Scans
The IM column store divides data into IMCUs, with each IMCU storing the equivalent of several hundred thousand database rows. There are three different ways in which Oracle Database libraries can perform scans of the IMCUs, and the method used depends on the underlying platform and platform-specific Oracle Database libraries:
- The default (generic) approach is a sequential memory scan that uses repetitive "load-compare" loops to obtain the data of interest. This approach provides a good level of performance representative of processor pipeline and memory speeds. Performance is limited by the rate of "load-compare" instruction execution.
- A better approach is the use of SIMD (single instruction, multiple data) vector processing. SIMD instructions, historically used for graphics processing, can process multiple data values in a single instruction cycle to provide better performance than generic instruction loops. Using specialized libraries, Oracle Database In-Memory can take advantage of SIMD vector instructions to achieve higher effective scan rates for query processing. Performance in this case is limited by core resources for SIMD processing.
- The optimal approach is to use Data Analytics Accelerator (DAX) units. On Oracle's SPARC servers featuring Software in Silicon, DAX units enable the most-efficient and fastest way of scanning IMCUs. Using DAX units is the most-efficient approach because DAX units offload much of the scanning tasks from the CPU cores. It is also the fastest approach because DAX units are effectively part of the SPARC processor memory controllers, and as such, memory bandwidth is the factor that constrains performance. See the companion article ("Architecture Matters: Accelerate Analytics with Oracle Database In-Memory and Software in Silicon, Part 2") for more details about DAX acceleration of Oracle Database In-Memory processing. Further, in the "Optimizing for Performance" section of "Architecture Matters, Part 3: Next Steps—Optimizing for Database Performance, Security, and Availability" you will see proof of the DAX accelerators working to help provide a 54x improvement on the analytical query being run.
In-Memory Storage Indexes
Another way in which Oracle Database In-Memory accelerates analytics is through the use of in-memory storage indexes. Each IMCU records metadata about its stored data, including minimum and maximum data values that comprise an in-memory storage index. When an analytical query includes a predicate (such as "show me all values WHERE amount is greater than x"), the scan examines the in-memory storage indexes and skips evaluating any IMCUs that contain out-of-range data for the evaluated expression.
In-Memory Optimized Joins and Aggregation
The Oracle Database optimizer can apply Bloom filters when joining tables, which can greatly reduce the amount of data processed by joins. When two tables are joined, a bit vector or Bloom filter is sent as an additional predicate to the second table's scan. Because Oracle Database In-Memory enables fast data scanning and predicate evaluation, optimized join operations can often execute more rapidly.
When processing complex queries that aggregate data, the optimizer also evaluates whether to apply an in-memory aggregation (IMA) optimization known as VECTOR GROUP BY. VECTOR GROUP BY reduces queries on typical star schemas into a series of filtered scans against dimension and fact tables, optimizing joins and computing aggregations using CPU-efficient algorithms. The relative advantage of IMA optimizations increases as queries become more difficult (requiring more joins of dimension tables to the fact table and aggregation over many grouping columns and fact rows). Note that the optimizer applies VECTOR GROUP BY depending on execution cost (no application changes are required).
Optimal Use Cases
Because of the four features described above, Oracle Database In-Memory is best suited for analytical queries that scan large amounts of data, perform predicate evaluation, and use joins or aggregation to find patterns or trends, as illustrated in Figure 2. Queries are typically questions along these lines: "How did incentive offers during some time period impact sales?," "How did specific products sell on a store by store basis?," or "How often did customers purchase the same product month-to-month?."

Figure 2: Optimal use cases are analytical queries that perform large data scans, predicate filtering, and joins or aggregation.
Oracle Database In-Memory results in optimal performance gains for queries with these characteristics:
-
Queries that scan hundreds of thousands of rows or more. Scanning columns is faster than random reads of specific columns across many rows. However, some system resources are expended to maintain the in-memory column store and IMCUs. As a general rule of thumb, to realize performance gains for analytic workloads, the resources and time saved during data scans for queries must exceed the resources and time required to maintain those structures. Performance benefits become more apparent when scanning hundreds of thousands of rows, and will increase with scale. The architecture can scale effectively to support the processing of billions of data elements.
-
Queries that scan a subset of columns from wide tables. Key to the performance acceleration of Oracle Database In-Memory is the ability to intelligently "skip" data that's not required for analytics processing. When a subset of columns in a wide table is scanned as part of analytical queries, the system can access just the needed columns from the IM column store, which yields significant performance gains. Conversely, if most or all columns in wide tables are scanned for query processing, it's often possible to read all columns in the buffer cache row store just as efficiently. As a general rule of thumb, queries that return just a few columns from wide tables will demonstrate a greater performance gain using Oracle Database In-Memory.
-
Queries that use filter predicates such as WHERE clauses that evaluate expressions using =, >, <, between, or in-list, returning a relatively small subset of scanned data. Oracle Database In-Memory applies WHERE clause filter predicates without first decompressing the data, so there's less data to scan and less data to actually evaluate. Scans also check the in-memory storage indexes, pruning out any IMCUs with minimums and maximums where the data does not satisfy the required predicates (as depicted in Figure 2). This check eliminates unnecessary scanning and filtering of IMCUs, saving valuable processing time. As a general rule of thumb, queries that return a tiny fraction or summary of data from a large quantity of scanned data generally see an improvement from Oracle Database In-Memory.
-
Queries that require joins or aggregation, reducing the amount of data returned. SQL statements that join multiple tables can also be converted into fast column scans that are rapidly processed in the IM column store. Join operations can take advantage of Bloom filters, transforming a join into a filter that's applied when scanning the larger table. Oracle Database In-Memory also speeds up complex IMA using the new VECTOR GROUP BY optimization for processing star schemas. As a general rule of thumb, queries that perform joins or aggregations across a sparse subset of columns in wide tables are good use cases for Oracle Database In-Memory.
The paper "Oracle Database In-Memory: In-Memory Aggregation" shows how the optimizer automatically applies this optimization to speed query response times for sample ad-hoc, batch, and dashboard queries. In this paper, IMA was shown to be on average 7.0 times faster than conventional query processing, while at the same time providing the most-consistent query performance and the best scale. The biggest performance boost was seen with the most-difficult queries (those that aggregated the most fact rows and joined the largest number of dimension tables to the fact table.)
-
Mixed workloads with a high query rate relative to transactional updates to column data. Oracle Database In-Memory asynchronously updates the IM column store when updates occur to column entries. In mixed workloads, if there are many queries (especially over combinations of columns in the same tables) compared to the number of transactions updating those columns, the IMCUs are rebuilt infrequently. As a general rule of thumb, if there is a high rate of queries relative to transactions that trigger a rebuild of IMCUs, there can be a potential benefit from using Oracle Database In-Memory.
Guidelines for Optimizing Analytics
When you are using Oracle Database In-Memory and running mixed workloads, one of the simplest performance optimizations is to remove analytic indexes from the relational database—otherwise, valuable system resources are spent on unnecessarily updating the indexes after OLTP transactions. There are several additional principles that can help to optimize query performance:
- Process data in the database, not in the application. Instead of reading rows out of the database into the application to perform a calculation, such as a total or an average, it is far more efficient to push those kinds of computations down into the database.
- Process data in sets, rather than row by row. Database entry and exit implies some overhead, but this overhead is offset when there is a large number of rows to process.
- Use representative optimizer statistics. Oracle recommends that DBAs follow best practices for gathering representative statistics. See the Oracle Database In-Memory blog post "What to do with optimizer statistics when upgrading to Oracle Database 12_c_ to take advantage of Oracle Database In-Memory."
- When possible, use parallel SQL. Using all available CPU cores for analytics processing is essential to maximize performance. Setting
PARALLEL_DEGREE_POLICY to AUTOMATIC allows the query to be automatically parallelized across all available cores.
Applications that don't follow these principles might see some degree of performance gain; in this case, modifications might be required to take full advantage of Oracle Database In-Memory. To learn more about optimal use cases, see the paper "When to Use Oracle Database In-Memory."
Getting Started with Oracle Database In-Memory
Before implementing Oracle Database In-Memory, it's important to profile an existing workload and consider how this option can effectively speed up analytical query performance. If the application has a bottleneck unrelated to analytics processing, data scanning, or SQL query execution, Oracle Database In-Memory might not help to improve performance—it cannot fix underlying nonanalytics performance issues. That said, in cases where intensive data I/O activity resulted because of full table scans, Oracle Database In-Memory has helped significantly.
Figure 3 (from the paper "When to Use Oracle Database In-Memory") breaks down the time spent for different functions within a typical analytics application. As this figure suggests, there are two areas that can see potential benefits when using Oracle Database In-Memory: analytics and reporting; and the maintenance of analytic indexes. Once Oracle Database In-Memory is implemented and fully evaluated, some indexes can be temporarily hidden and then potentially dropped, which improves application performance, especially with mixed workloads.
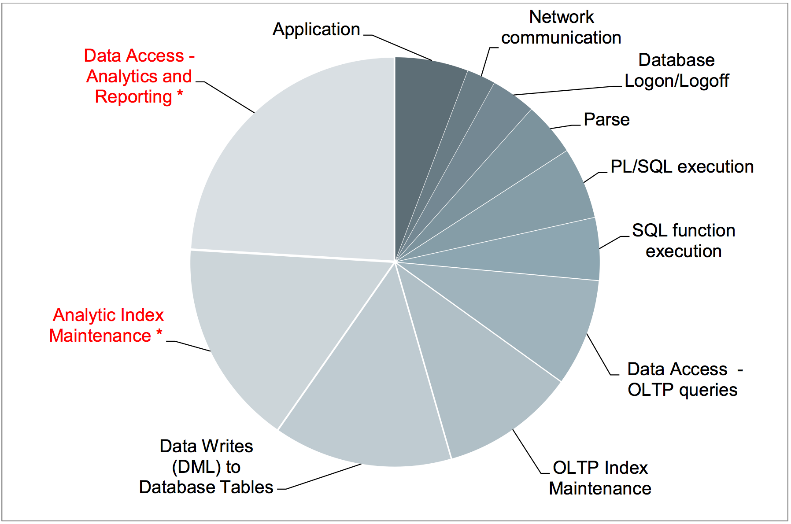
Figure 3: Where Oracle Database In-Memory shows a performance benefit.
Perhaps the biggest takeaways from Figure 3 are the areas that do not benefit from Oracle Database In-Memory because they are unrelated to analytics or SQL execution. Understanding where an existing application spends processing time is helpful in understanding whether the application will gain a performance benefit from Oracle Database In-Memory.
The blog "How do I identify analytic queries that will benefit from Oracle Database In-Memory?" gives a simple example of examining a query's execution plan before initializing Oracle Database In-Memory. The following query accesses a single table and generates an SQL Monitor report pointing to a performance bottleneck for data scanning and filtering (Figure 4):
SELECT /*+ MONITOR */ Count(*), SUM(lo_profit)
FROM lineorder l
WHERE lo_custkey BETWEEN 48000 AND 48500;
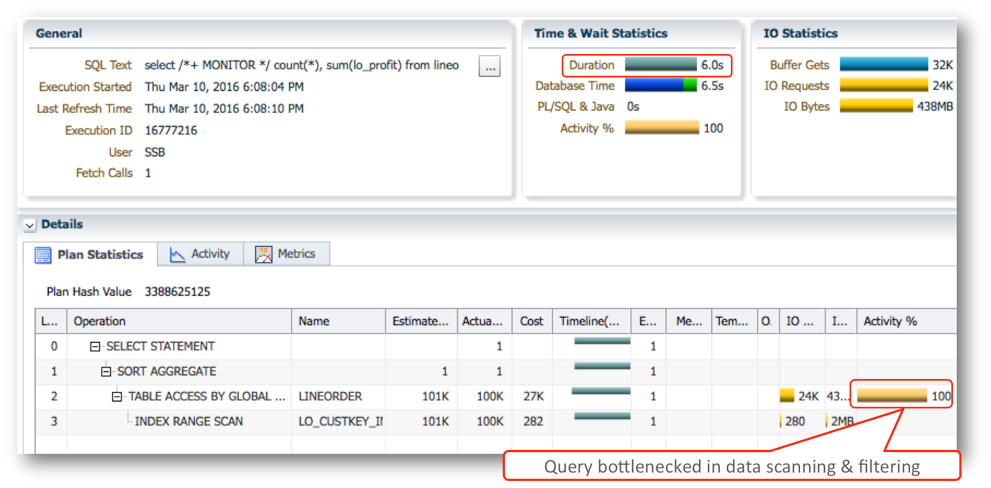
Figure 4: SQL monitor report indicates that table scanning and filtering is the bottleneck.
Because this sample query focuses on two columns in a 20-column table, features a predicate to be evaluated, and spends the majority of time in the table scan, it is potentially a good candidate for Oracle Database In-Memory. After labeling the table with the INMEMORY attribute to populate it into the IM column store, rerunning the query lowers the query duration from 6.0 seconds to 0.3 seconds.
While this query is a simple example, it illustrates the concepts of establishing a performance baseline, generating an SQL monitor report, and examining SQL execution plans and statistics. (Additional examples of how execution plans and statistics can help to optimize performance are topics in the blog posts: "How do I identify analytic queries that will benefit from Database In-Memory?" and "Memory Usage with Oracle Database In-Memory.")
Along with application profiling and diagnostics, consider these other implementation planning aspects and best practices when adopting Oracle Database In-Memory:
-
Install the latest bundle patches for Oracle Database 12_c_. Oracle Database In-Memory is an option for Oracle Database 12_c_, and the latest bundle patches are recommended for the best performance. If a database upgrade is required, it's recommended to focus on moving to Oracle Database 12_c_ and establishing known execution plans that provide the same (or better) performance before evaluating the performance of Oracle Database In-Memory. Be sure to capture current optimizer statistics and execution plans prior to the database upgrade.
-
Determine the optimal size for the IM column store. Oracle has released two tools designed to help estimate size requirements:
- Use the In-Memory Advisor to predict what objects are best populated in the IM column store. It analyzes Active Session History (ASH) and Automatic Workload Repository (AWR) data to predict what analytic workloads will benefit most from Oracle Database In-Memory and what objects should be placed in the store. The In-Memory Advisor is licensed as part of the Database Tuning Pack and relies on data coming from the Database Diagnostic Pack. It can be run on Oracle Database 11.2.0.3 and above to help plan the transition to Oracle Database 12_c_ with the Oracle Database In-Memory option. (To download the In-Memory Advisor, see My Oracle Support note 1965343.1.)
- Use the Compression Advisor feature of Oracle Database 12_c_ to estimate compression ratios for different database objects. Running the Compression Advisor can help to determine memory requirements because it estimates how much space an object will consume in the IM column store, based on the chosen compression level. (See "Managing Table Compression Using Oracle Enterprise Manager Cloud Control" in the Oracle Database Administrator's Guide.)
-
If possible, increase the size of the SGA by the estimated size of the IM column store you plan to create. This is usually done by adding more memory to the bare-metal server or virtual machine for the database instance, and then manually increasing the size of the SGA or enabling automatic memory management (AMM). If it is not possible or practical to increase the size of the SGA, expect the buffer cache pool to shrink by the size of the newly added IM column store. In this case, care must be taken to determine the impact of a smaller buffer cache pool size on performance, especially with respect to how it might affect transaction processing performance.
-
Allocate memory for the IM column store and restart the database. Oracle Database In-Memory is not enabled by default (see the blog post "Getting started with Oracle Database In-Memory Part I — Installing and Enabling"). Based on object sizing and compression estimates, specify the size of the SGA IM column store using the parameter INMEMORY_SIZE to configure Oracle Database In-Memory. (In sizing the SGA IM column store, make sure that the SGA_TARGET can accommodate other processing concurrently). Restart the database so that modified memory allocations take effect.
-
Verify performance on Oracle Database 12_c_. Run a sample analytic query workload on Oracle Database 12_c_ without Oracle Database In-Memory (that is, before populating tables or other objects in the IM column store). This will be the baseline (reflecting any modified SGA allocations) to capture execution statistics and judge how much Oracle Database In-Memory can improve performance. If there are no additional performance issues or tuning requirements, then it's time to populate the IM column store and evaluate performance with Oracle Database In-Memory. (See "What to do with optimizer statistics when upgrading to Oracle Database 12_c_ to take advantage of Oracle Database In-Memory.")
Final Thoughts
Recognizing the value of business intelligence, Oracle offers an in-memory database option for real-time analytics that complements and extends the existing Oracle Database 12_c_ product family. The Oracle Database In-Memory option enables fast analytic queries on Oracle Database 12_c_ instances, allowing both analytics and conventional OLTP applications to execute with transactionally consistent data. Oracle Database In-Memory is trivial to implement and its use requires no application changes. In addition, it is fully compatible with other Oracle Database 12_c_ options such as Oracle RAC.
For more information about Oracle Database In-Memory, visit the website or contact your Oracle representative. The first step to deploying seamless business analytics is to profile existing analytical query and reporting applications, examine SQL execution plans, and determine if the application has the optimal characteristics to benefit from Oracle Database In-Memory. After that, implementing a proof-of-concept evaluation is the next logical step.
Oracle Database In-Memory can accelerate analytical queries regardless of the underlying hardware platform, but running this analytics solution on SPARC processors in the Oracle's latest servers can often provide an additional performance boost. The next article, "Architecture Matters: Accelerate Analytics with Oracle Database In-Memory and Software in Silicon, Part 2," explains how on-chip DAX units speed up the performance of Oracle Database In-Memory applications.
See Also
About the Authors
Randal Sagrillo is a solutions architect for Oracle. He has over 35 years of IT experience and is an expert in storage and systems performance, most recently applying this expertise to next-generation data center architectures, integrated systems, and Oracle engineered systems. Sagrillo is also a frequent and well-attended speaker on database platform performance analysis and tuning and has spoken at several industry conferences including Oracle OpenWorld, Collaborate, Computer Measurements Group, and Storage Networking World. In his current role, he is responsible for solution architecture and development around Oracle Optimized Solutions. Before joining Oracle, he held a variety of leadership roles in product management, program management, and hardware/software product development engineering.
Ken Kutzer is a team lead for Oracle Optimized Solution for Secure Oracle Database and Oracle Optimized Solution for Oracle Database as a Service. He is responsible for driving the strategy and efforts to help raise customer and market awareness for Oracle Optimized Solutions in these areas. Kutzer holds a Bachelor of Science degree in electrical engineering and has over 20 years of experience in the computer and storage industries.
Larry McIntosh is the chief architect within the Oracle Optimized Solutions team. He has designed and implemented highly optimized computing, networking, and storage technologies for both Sun Microsystems and Oracle. McIntosh has over 40 years of experience in the computer, network, and storage industries and has been a software developer and consultant in the commercial, government, education, and research sectors and an information systems professor. He has directly contributed to the product development phases of Oracle Exadata Database Machine and various Oracle Optimized Solution architectures. His most recent contribution has been in the design, development, testing, and deployment of Oracle Optimized Solution for Secure Oracle Database.