by Randal Sagrillo, Larry McIntosh, and Ken Kutzer
This article describes the operation of Oracle's SPARC processor Data Analytics Accelerator (DAX) technology and how it is applied to accelerate analytical queries. A companion article (Part 1) describes how the Oracle Database In-Memory option for Oracle Database 12_c_ accelerates data analytics, its optimal use cases, and how the software interacts with infrastructure hardware.
Table of Contents
Introduction
What Are DAX Units?
Query Offload and Acceleration
High Memory Bandwidth
High-Speed Data Decompression in Hardware
Performance Impact - Mixed Workload Example
DAX Integration with the Oracle Solution Stack
Accelerating Analytics Outside of Oracle Database
Final Thoughts
See Also
About the Author
|
Introduction
Companies increasingly rely on real-time analytics to improve strategic decision-making, analyzing large data sets to reveal important patterns or trends. To accelerate analytical queries, Oracle offers the Oracle Database In-Memory option for Oracle Database 12_c_. While these products are supported on a wide variety of systems, there are specific advantages to running them on SPARC platforms that offer Software in Silicon (SWiS) capabilities. This article describes an important element of SWiS technology, the on-chip Data Analytics Accelerator (DAX) units. It explains how DAX units offload query scan and decompression tasks from the SPARC cores, and how improved data flow helps to speed query processing. It also highlights the performance impact of applying DAX units, and provides configuration guidelines for using them in conjunction with Oracle Database In-Memory. Lastly, this article touches on using DAX units for other analytic applications in addition to Oracle Database In-Memory queries.
| |
|

Oracle Optimized Solutions provide tested and proven best practices for how to run software products on Oracle systems. Learn more.
|
|
It is recommended that readers who are not familiar with Oracle Database In-Memory review the companion article, "Architecture Matters: Accelerate Analytics with Oracle Database In-Memory and Software in Silicon, Part 1." Part 1 describes the Oracle Database In-Memory option for Oracle Database 12_c_, how it functions, its configuration and setup, and optimal use cases in which the software improves analytics and ad-hoc query performance.
What Are DAX Units?
Oracle has taken an innovative Software in Silicon (SWiS) approach with its SPARC processor design, incorporating hardware acceleration and security features directly into the processor for faster and more-reliable enterprise computing results. As a part of the SWiS approach, SPARC processors include on-chip DAX units that can improve the performance of analytic workloads, enable the processing of larger data sets, and achieve query response times that aren't possible on other processor architectures. (To learn more about SWiS features, read "Software in Silicon: What It Does and Why.")
DAX units consume a very small portion of processor real estate (Figure 1), but can yield big performance gains for analytic queries. They speed up functions characteristic of Oracle Database In-Memory and general analytics applications, offloading critical operations from processor cores and improving performance for mixed workloads that include simultaneous analytic and OLTP activity.
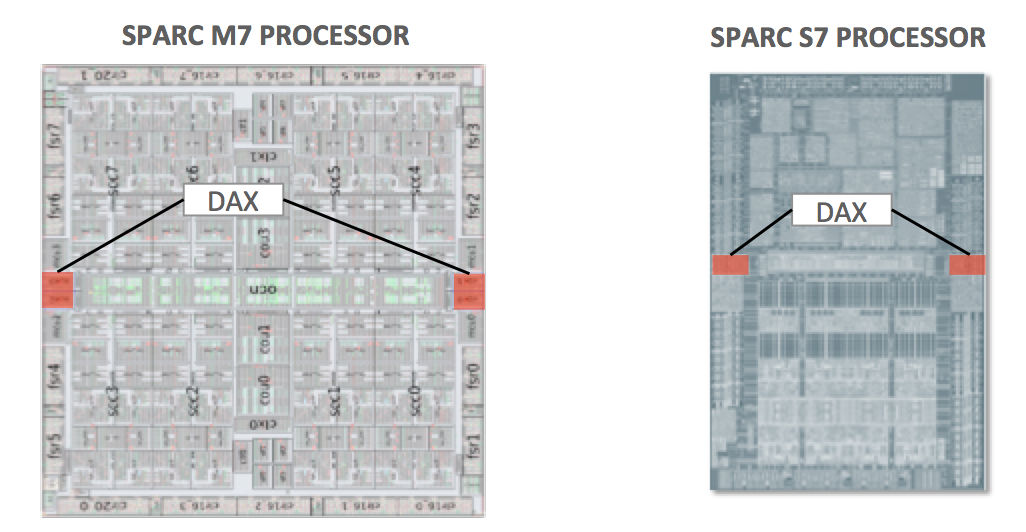
Figure 1. DAX units on SPARC M7 and SPARC S7 processors occupy only about 3 percent of the CPU footprint.
SPARC processors that include DAX units offer three substantial advantages when processing analytics:
- Query offload and acceleration: Performs common query processing tasks, such as scans, joins, and data filtering
- High memory bandwidth: Enables large data transfers required for analytic processing
- High-speed data decompression in hardware: Eliminates or minimizes the performance penalty of in-memory decompression operations
Query Offload and Acceleration
In traditional processor architectures, the processing associated with analytic queries takes place in the cores and requires the transfer of the complete data set to be analyzed. Both complex processing and large data transfers become limiting factors for performance. Additionally, the performance of other workloads on the system, such as transaction processing, can be impacted because of contention for the same resources.
On processor architectures that feature SWiS, much of the analytic processing can occur on the DAX units, with data transferring directly from memory to the DAX units while allowing the cores to perform other processing tasks. The net result is query acceleration while enabling more system resources to be available for other processing.
For a sample query, such as "show me all sales within the region California," Figure 2 illustrates the difference in data flow and processing in two different processor architectures: one with and one without DAX units. With the traditional architecture on the left, data for all regions is copied from memory to cache and then into the cores for processing. The memory bus, processor cache, and core resources are heavily taxed during this operation.
In contrast, when DAX units are used (as shown on the right), only the scan results that satisfy the scan predicate ("WHERE region = CA") are transferred to the core. Scan results are received much faster due to query acceleration in the DAX units while demand on the memory bus, L3 cache, and cores is greatly reduced because only the results are transferred for further processing.
DAX units provide an additional performance benefit related to the processor cache. By design, the system keeps frequently accessed information in the local processor cache for immediate use, even for SIMD vector processing. For a processor architecture without DAX units, when a large data set is moved into the processor core, the current data in the cache is evicted and no longer available for immediate use. This effect is called cache pollution. With DAX units, because most of the data is never moved into the core, cache pollution is minimized.
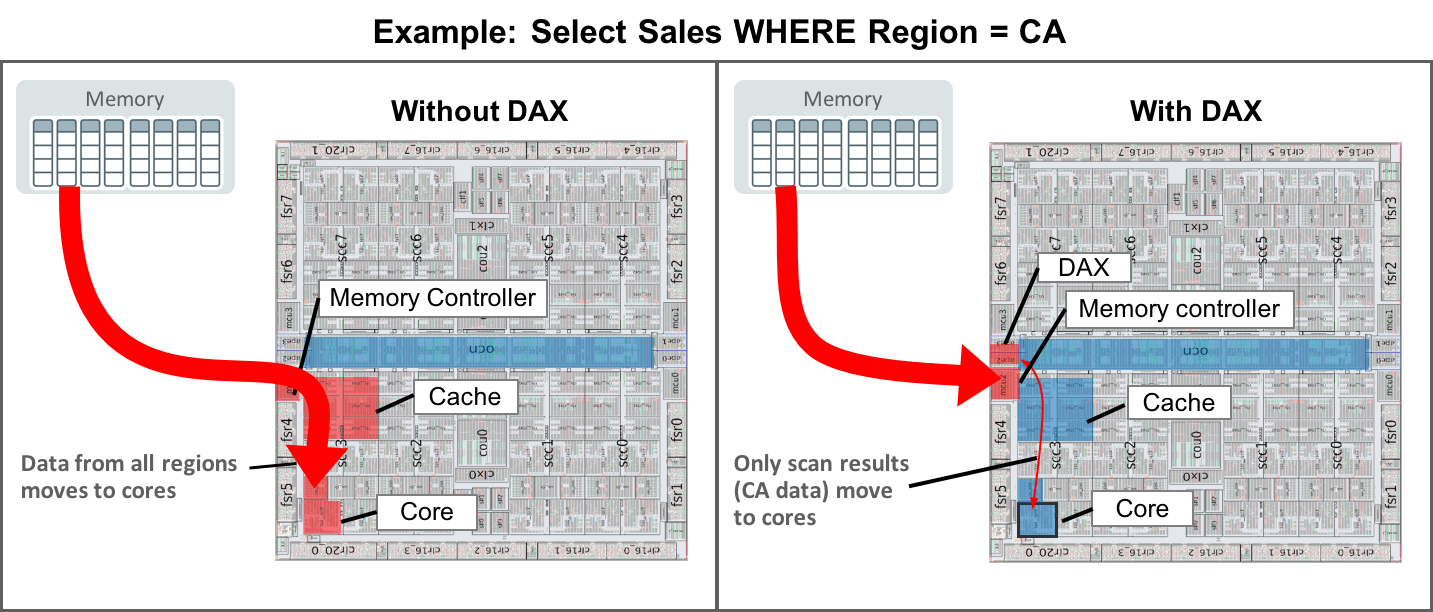
Figure 2. DAX units return only predicate results for efficient use of memory resources and bandwidth.
Within each DAX unit, there are four independent pipelines that can each simultaneously execute any of the following operations:
- Select: Filters data and returns only the data of interest
- Scan: Efficiently searches data and evaluates predicates (such as WHERE clause expressions)
- Extract: Accelerates data decompression, creating an unpacked output stream from an input stream
- Translate: Accelerates lookup operations typical in in-memory aggregation and big-to-small table joins
The DAX units and pipelines are not hardwired to certain cores on the SPARC processor—each core can submit work to any DAX unit on that CPU. When query processing is complete, a DAX unit typically stores its results in memory or in the L3 processor cache. When a monitored memory location is updated with DAX results or when a DAX processing timer expires, the core thread is reactivated. Until that time, the core is free to perform other work independent of the DAX pipelines. Please refer to the companion article (Part 1) to understand the ideal use cases for Oracle Database In-Memory; generally, the optimal use cases are analytic queries that scan large amounts of data, evaluate predicates, or use joins or aggregation to find patterns or trends.
High Memory Bandwidth
The ability to analyze larger data sets provides many benefits to data scientists, allowing them to find patterns that are not easily discernible, run more-complex models for higher accuracy, or process more scenarios in iterative "what if" analyses. While evaluating larger data sets offers these benefits, it places even larger demands on system memory bandwidth. This is because larger amounts of data must be moved around multiple times within the system to perform a single query. For example, a typical query requires scanning of large data sets for processing, but also requires large amounts of data to be decompressed as a part of that query. Moreover, Oracle Database and other modern analytics platforms perform query processing in parallel. This means that multiple cores and/or DAX units are performing multiple scans and decompression operations simultaneously.
Fortunately, SPARC processors are architected for this challenge. For both query processing and decompression tasks, the DAX units take advantage of the superior memory bandwidth and parallel processing capabilities available on SPARC processors, on both SPARC M7 processor–based systems and SPARC S7 processor–based platforms. Moreover, the DAX units have direct access to the memory bus, enabling data decompression and scan operations that execute at almost full memory bandwidth speeds—without data transfers through the processor cache and cores. Because of this, SPARC memory architectures with DAX units provide the highest levels of system efficiency when performing in-memory analytics. To read about a use case that shows how SPARC system cores work efficiently in parallel with the DAX units, see "Using the In-Memory Option with Software in Silicon Technology" in "Architecture Matters, Part 3: Next Steps—Optimizing for Database Performance, Security, and Availability."
High-Speed Data Decompression in Hardware
Oracle Database In-Memory utilizes data compression and decompression to increase the data available for immediate analysis. The challenge, however, is that data compression and decompression algorithms can be resource-intensive, generate latency, and slow down overall performance. For this reason, there are tradeoffs that should be evaluated, and this section provides insight into the underlying technologies and considerations.
In-Memory Compression
The companion article (Part 1) describes how Oracle Database In-Memory, independent of the underlying hardware platform, stores columns in the in-memory column store (IM column store), a memory area allocated and sized by the database administrator (DBA). The IM column store is a static memory pool in the Oracle Database System Global Area (SGA) that supplements the row-oriented SGA buffer cache. Part 1 also explains how Oracle Database In-Memory divides data in the IM column store into in-memory compression units (IMCUs), with each IMCU storing the equivalent of several hundred thousand database rows. As the name indicates, IMCUs commonly use one or more compression techniques, condensing data columns in the IM column store (which in turn reduces the required allocation of SGA and main memory for the IM column store). The compression level is set by the DBA on a table-by-table basis (see "Using the In-Memory Column Store" in the Oracle Database Administrator's Guide).
An assumption in compressing column data is that the IMCUs will be scanned many times as a part of analytical query processing. If this is not the case, it is likely that the execution plan will process queries out of the buffer cache instead of using the IM column store. For this reason, IMCUs can be thought of as write-once (or maybe write-few) and read-many data structures. This write-once/read-many nature frames the tradeoffs that the DBA should consider when using Oracle Database In-Memory and the IM column store, as outlined in Table 1. There are many benefits of storing columns in a compressed format, and these advantages are usually platform-independent. In contrast, many of the tradeoffs listed below do not apply to in-memory query processing on DAX units, as subsequent sections of this article will show.
Table 1. Compression Benefits and Tradeoffs
| IMCU Compression Advantage | IMCU Compression Benefit | IMCU Compression Tradeoff |
| Compressed IMCUs reduces the necessary allocation of SGA and main memory for the IM column store. | DBA can fit more table column data in each database node, which can deepen analysis and simplify management.
Compressed IMCUs require less space for the IM column store. A side effect is that more space remains available for the buffer cache, which can help to optimize performance, particularly for mixed analytics and OLTP workloads. | Higher levels of compression are more compute-intensive, which can potentially slow query processing by creating a processing bottleneck. |
| Compressed IMCUs allow for higher effective column scan rates (more effective rows per section scan rate). | Higher effective scan rates improve analytic query throughput for higher business decision throughput and operational efficiency.
Higher effective scan rates can shorten analytic query time, improving business responsiveness. | Higher levels of compression can take more computing resources to decompress IMCUs prior to scanning, which can potentially slow query processing by creating a processing bottleneck.
Higher levels of compression can take longer to decompress prior to scanning, which can impact query time and business responsiveness. |
Types of Compression
To better understand the tradeoffs of various compression levels applied to in-memory database tables, it is helpful to understand the types, scope, and layering of the underlying compression technologies.
When using Oracle Database In-Memory and loading performance-critical analytical data into the IM column store, DBAs can specify different compression settings using the MEMCOMPRESS keyword, as shown in Table 2:
Table 2. Compression Options
| Compression Option | Description |
| NO MEMCOMPRESS | Data is populated without compression. |
| MEMCOMPRESS FOR DML | Minimal compression; optimized for DML performance. |
| MEMCOMPRESS FOR QUERY LOW | Default: Optimized for query performance; decompression and offload are automatically enabled. |
| MEMCOMPRESS FOR QUERY HIGH | Optimized for query performance with a bias towards saving space; OZIP compression is enabled, decompress and scanning operations are performed in a single fused step. |
| MEMCOMPRESS FOR CAPACITY LOW | Greater bias toward saving space; OZIP compression is enabled, and two steps are required for decompression/scan operations. |
| MEMCOMPRESS FOR CAPACITY HIGH | Optimized to conserve space. |
Different MEMCOMPRESS settings result in the use of different compression algorithms:
- Bit-packing efficiently compresses multiple small integers together into the space typically used for a single integer (usually 32 or 64 bits). With Oracle Database In-Memory, this algorithm is sometimes applied in addition to other compression techniques.
- Dictionary encoding substitutes a value from a separate data structure (or "dictionary") representing the data value. This method is most effective when the data has low cardinality (that is, only a small number of unique values).
- Run-length encoding (RLE) compresses data by representing consecutive instances of the same data value using a single data value and count.
- OZIP substitutes a value from a fixed-size static dictionary generated from a random sampling of input data. OZIP is an Oracle-developed compression algorithm that enables the fastest and most efficient decompression using DAX units.
When applied to columnar data in the IM column store, dictionary encoding is typically used in combination with bit packing. In this approach, row values are replaced with a "dictionary"' key value. The range of the key values depends on the cardinality of the data. For example, if a column has only the potential values of DAY and NIGHT, the row value can be encoded using a single bit (this data has very low cardinality). A more interesting example is a data column with row values that correspond to the 50 states of the United States. In this example, the data has a cardinality of 50, which can be expressed in just 6 bits!
Figure 3 shows how fields with lower cardinality can often be used to identify trends of interest for many analytical queries. Packing these row values into only a few bits greatly increases the effective column scan rates and reduces the amount of memory needed to store the in-memory column data.
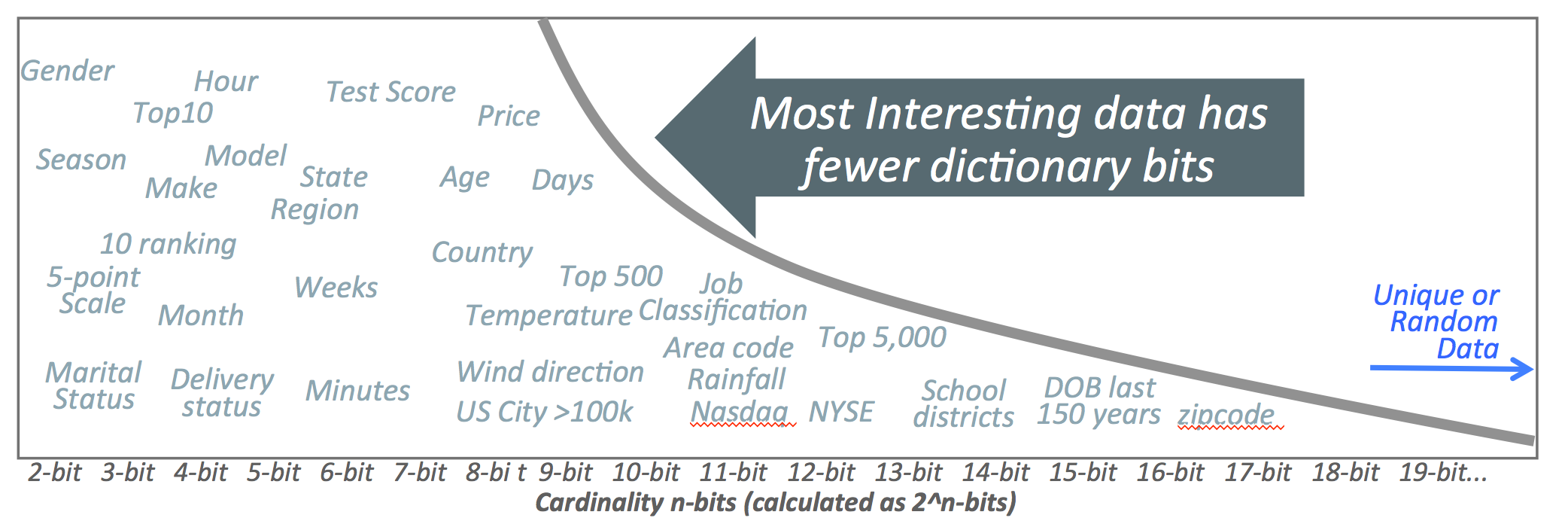
Figure 3. Lower cardinality data is often the data of interest.
On a SPARC system with DAX units, the MEMCOMPRESS FOR CAPACITY LOW setting compresses both the IMCU headers and data for Oracle Database In-Memory applications that require a greater bias toward saving space (Figure 4). To optimize analytic query performance, MEMCOMPRESS FOR QUERY HIGH (highlighted in Table 2) uses OZIP compression to compress only the data in the IMCUs. QUERY HIGH allows DAX pipelines to perform efficient decompression and scanning in a single, fused operation. Without DAX units, QUERY HIGH results in the use of RLE, which results in a two-step operation by the cores: first decompressing the data and writing it out to memory, and then rereading it to perform the scan. The default setting, MEMCOMPRESS FOR QUERY LOW, uses dictionary encoding to optimize query performance across all system types. When optimizing for query performance, the QUERY HIGH setting on systems with DAX units is recommended to achieve fast, one-step OZIP decompression.
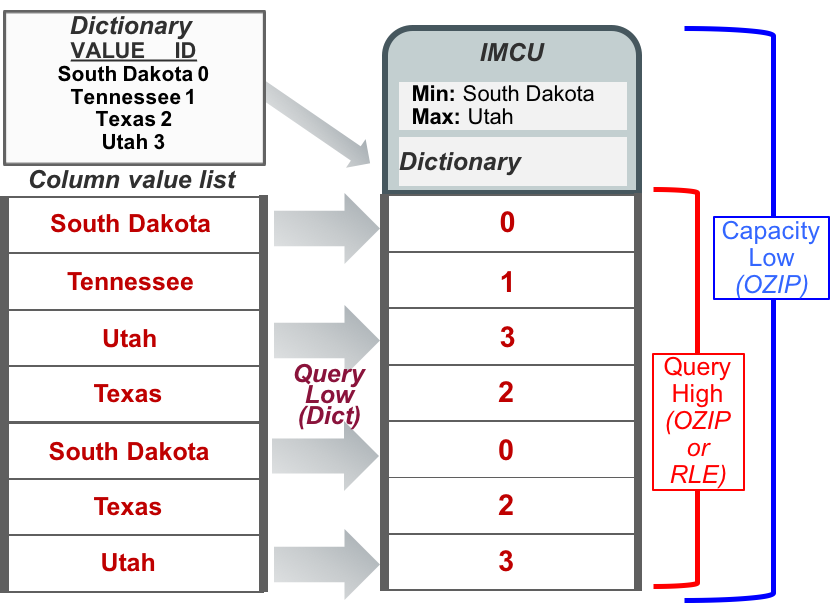
Figure 4. Multiple types of compression/encoding used by Oracle Database In-Memory.
On all platforms, it is recommended to test workloads using different MEMCOMPRESS settings, including NO MEMCOMPRESS (no compression) to establish a performance baseline. Compression ratios can vary from 2x–20x, depending on the compression method, the type of data, and the data values. The compression technique can also vary across columns or partitions within a single table. The Oracle Database Compression Advisor (DBMS_COMPRESSION) can supply an estimate of the in-memory compression ratio.
Decompression with DAX Units
Compression offers significant benefits for analytics, regardless of the underlying platform: it enables the analysis of larger data sets (improving the fidelity of query results) while producing real-time answers to business intelligence questions. All platforms today use CPU cores to compress (encode) IMCUs. Because IMCUs operate in a write-once/read-many mode for query processing, the invested cost of compressing IMCUs is amortized over the benefits of using compression.
Decompression, however, is a notoriously compute-intensive task. Because DAX units efficiently offload data decompression from the CPU cores, it's possible to realize the advantages of compressing data in memory without performance tradeoffs. Larger database objects can fit in memory, and bandwidth is used more efficiently, resulting in faster query execution and better outcomes.
Moreover, because DAX units can decompress and scan in a fused manner (in a single memory pass), they offer a significant advantage over other platforms for Oracle Database In-Memory implementations. The benefits for analytics are multiplied because
- The single-step, fused decode and scan operations on columnar data eliminate additional scanning time and conserve query processing resources. CPU resources are not required to perform an additional or separate decompression step for the column data before performing a column scan.
- DAX units are closely associated with the processor's memory controller and can execute instructions off-core, so they are limited only by memory bandwidth and the time it takes to set up or program the DAX units to perform selects, translates, and fused scans.
- Offloading the CPU cores minimizes the impact on overall system performance when applying higher compression levels, further mitigating any tradeoff between compression's impact on performance and its advantages.
Without DAX acceleration, the work of decompression is the responsibility of the cores: the cores must read in compressed data from memory, write the scanned data to cache, reread the data from cache, decompress it, and then write out the query results. DAX units, on the other hand, can decompress and scan data in as little as a single step, eliminating multiple reads and writes. The result can be in-line decompression and query processing at full memory bandwidth speeds—greater than 120 GB/second per SPARC M7 processor.
Ultimately for a wide variety of workloads, Oracle's SPARC processors with on-chip DAX units can provide more benefits—real-time queries, higher solution efficiency, and greater solution effectiveness—with fewer tradeoffs, increasing flexibility for DBAs.
Performance Impact—Mixed Workload Example
The blog "Simultaneous OLTP and In-Memory Analytics: SPARC T7-1 Faster Than x86 E5 v3" describes a benchmark that demonstrated superior performance and throughput for a combination of OLTP transactions and analytical queries using Oracle Database In-Memory. In this benchmark, a SPARC T7-1 server from Oracle with a single SPARC M7 32-core processor (with eight on-chip DAX units) ran sample queries 8.2 times faster, at the same time enabling 2.9 times higher OLTP transaction throughput in comparison to an x86 server with two 18-core Intel Xeon E5-2699 v3 processors (Figure 5).
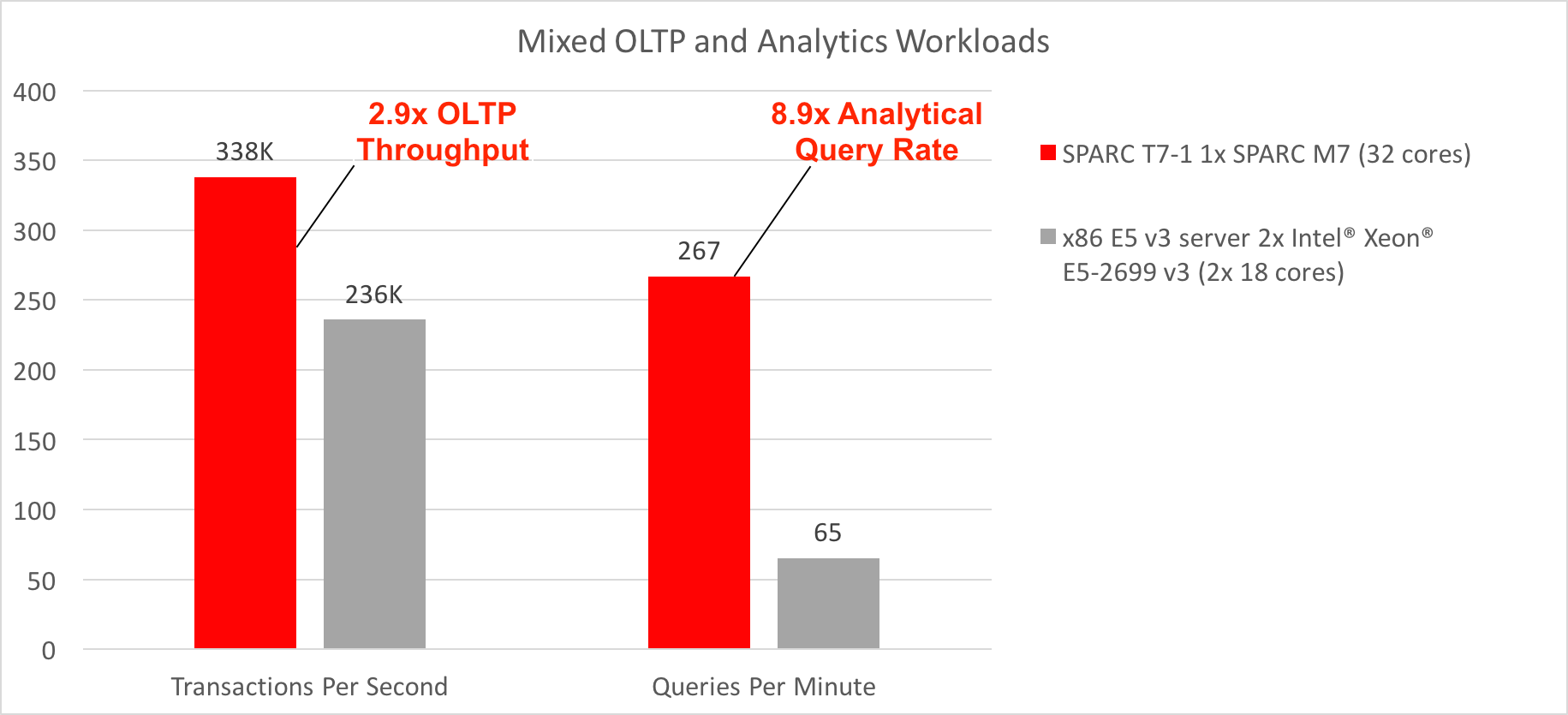
Figure 5. A single SPARC M7 processor showed impressive results for a mixed OLTP and analytics workload in comparison to two Intel Xeon E5-2699 v3 processors.
Because SPARC processor–based systems can support fast analytics on OLTP databases, organizations can often deploy a smaller database infrastructure footprint to do the same work as generic systems. And fewer systems, of course, can mean less IT complexity, reduced power costs, and simplified, less costly administration.
DAX Integration with the Oracle Solution Stack
To optimize Oracle Database In-Memory queries on OLTP databases, Oracle carefully integrated DAX functionality into the hardware and software stack so that SPARC processor–based systems can accelerate processing easily, without the need for application changes, tuning, or complex configuration steps. DAX acceleration is automated and transparent across the application, database, operating system, virtualization, and hardware layers.
At the database layer, Oracle Database 12_c_ invokes a high-performance kernel (HPK) library specific to the underlying CPU architecture. On SPARC processor–based systems that feature DAX capabilities, an additional DAX-specific library is dynamically loaded, and it is this library that dispatches low-level DAX processing calls.
When a SPARC core receives an Oracle Database In-Memory query, the following occurs:
1. The core halts the currently executing thread.
2. It then composes a query plan to coordinate execution between the DAX units and the core.
3. The query plan offloads certain operations to the DAX units.
Offloaded tasks are those that the DAX units can perform efficiently, such as comparisons, set membership, dictionary decoding and projection, expanding an RLE bit vector, and OZIP decompression. Figure 6 illustrates how a query plan might allocate a set of query processing tasks between the cores and DAX units. While it takes some time for the core to build the query plan, other aspects of the core-to-DAX offloading process are extremely fast because bandwidth is used so efficiently and DAX execution itself is rapid.

Figure 6. The query plan coordinates the efficient use of SPARC processor core and DAX resources.
Oracle Database 12_c_ with the Oracle Database In-Memory option is responsible for efficiently planning query execution whether using DAX units or not. The Oracle Solaris kernel and the Oracle VM Server for SPARC hypervisor are responsible for automatically offloading processing to the DAX pipelines, negotiating virtual-to-physical address translations, composing execution control blocks, and transforming HPK calls into low-level DAX instructions. No application changes are required to apply the processing power of DAX units to Oracle Database In-Memory analytics.
Virtualization and DAX Operation
DAX acceleration is fully integrated with the virtualization layer of the Oracle solution stack. On SPARC processor–based platforms, the Oracle VM Server for SPARC hypervisor allocates memory and core resources to virtual machines (VMs) known as logical domains (LDOMs). When an administrator assigns system resources to these VMs, no special layout or tuning tasks are needed to take advantage of DAX acceleration.
This is because DAX units are associated with physical memory channels and the physical memory DIMMs attached to them—thus DAX units are fully virtualized just like any other processor resource. If cores and memory are allocated to a logical domain, the associated DAX units and their pipelines are also allocated and mapped to those cores. Because potential performance bottlenecks for DAX units are associated with the memory bandwidth of the attached memory and the time needed to program the units via the cores, no special layout or tuning tasks are required to take advantage of DAX acceleration. In other words, even if only a portion of the VMs on a system are used for running databases, all DAX units available to those databases will use all the memory bandwidth given to those VMs; there would be no performance advantage in trying to allocate additional DAX units to database VMs, even if you could. Obviously, adding more memory (and, hence, memory channels and memory bandwidth) can often improve database VM performance, but adding additional DAX units themselves does not. Likewise, any named resource used by any type of Oracle Solaris Zone (such as a processor core or memory and its associated DAX units) can be virtualized with the same high degree of utilization, efficiency, and query performance as other named resources used by zones.
Optimizing Oracle Database In-Memory for DAX Use
To get started using Oracle Database In-Memory and take advantage of DAX acceleration, it's recommended to first profile the application and size the performance-critical database tables. It's also necessary to configure the SGA's In-Memory Area. For set-up procedures and guidelines, refer to "Using the In-Memory Column Store" in the Oracle Database Administrator's Guide. To confirm that the In-Memory Area is configured for Oracle Database In-Memory and that the DAX units are operating and accelerating queries, see the section "Using the In-Memory Option with Software in Silicon Technology" in "Architecture Matters, Part 3: Next Steps—Optimizing for Database Performance, Security, and Availability."
Taking advantage of innovative technologies in an Oracle solution stack is easy. Because stack components are highly integrated, implementations can often benefit from these technologies simply by deploying stack components together. When using Oracle Database In-Memory on SPARC server architectures that include SWiS and DAX units, there are a couple of best practices to remember:
- Be sure to set PARALLEL_DEGREE_POLICY=AUTO. Even though the DAX units offload the cores, this setting is used to manage core consumption on all platforms. By allowing multiple DAX units to process in parallel, this setting helps to increase overall performance and efficiency of analytics processing.
- While the best way to tune compression settings is to establish a baseline and try different MEMCOMPRESS settings, when using systems with DAX units, it is highly recommended to start with MEMCOMPRESS FOR QUERY HIGH. This setting enables the fused (single pass) scan/decode operation for IM column store data, enabling higher levels of compression with little added cost for repetitive analytics.
Accelerating Analytics Outside of Oracle Database
While the focus of this article has been SWiS and the benefits of applying DAX units for Oracle Database In-Memory analytics, Oracle has published an open API for DAX to enable the use of DAX functionality for broader analytics application needs. This API allows other analytics applications—such as those that examine big data to detect hidden patterns, customer preferences, or trends—to leverage DAX acceleration and the high memory bandwidth available in Oracle's SPARC servers.
DAX units can help to speed up processing tasks for many typical big data applications, including
- Pattern processing and discovery
- Fraud and intrusion detection
- Risk-based authentication
- Recommendations on buying patterns or new trends
- K-means clustering for machine learning and data mining
- K-nearest neighbor (KNN) for classification and regression
Because these types of applications typically examine large data sets to discover distinct patterns and correlations (conducting analysis and identifying trends for strategic business decisions), many are good use cases for DAX acceleration and can benefit from the high processor-to-memory bandwidths in Oracle's servers with SPARC S7 or SPARC M7 processors. Applications that perform numerous memory scans, such as those that sort data or search unsorted data, are the types of applications that can see a substantial performance boost from the use of DAX units.
To evaluate the impact of DAX acceleration for a typical big data analytics application, Oracle engineers conducted testing using the open source Apache Spark cluster-computing framework. The article "Apache Spark and SPARC M7 Data Analytics Accelerator" describes how executing a Java language–based Apache Spark application on DAX units was six times faster than running the same application without DAX units.
Oracle publishes the DAX APIs in both C and Java, and there are two libraries available: a library that provides thread-safe access to the underlying DAX technology, and a vector library that abstracts DAX operands as vectors. Oracle also makes test environments available to registered users on Oracle Software in Silicon Cloud (http://swisdev.oracle.com/). After registering at this site, developers—such as Oracle partners, SPARC enterprise developers, and university researchers—can access ready-to-run VMs hosted on a SPARC M7 processor–based server. In addition, developers can access provided code examples and begin using the DAX APIs in a free, secure cloud setting.
Final Thoughts
DAX units can provide substantial performance gains for business analytics and Oracle Database In-Memory queries, and can do so with tremendous efficiency. Clocked at half the frequency of a processor core, DAX units are also efficient from a power consumption standpoint, using little power and yet providing a significant speed-up for query processing. To help customers deploy a complete Oracle Database 12_c_ solution quickly and with less risk, Oracle offers Oracle Optimized Solution for Secure Oracle Database—a comprehensive end-to-end Oracle architecture built on Oracle's SPARC processor–based servers and validated for advanced security, availability, and performance. In this solution, Oracle Database In-Memory enables extremely fast analytics using DAX units and high memory bandwidth—accelerating data scans, inline decompression, predicate filtering, joins, and aggregation operations—all without application changes. While speeding up analytics, DAX units also free the processor cores, which can lead to better performance for mixed OLTP and analytical workloads.
To get started and learn how to accelerate your business analytics, the first step is to begin profiling database queries using the Oracle Database In-Memory option on Oracle Database 12_c_. The next step is to evaluate query performance on Oracle's SPARC processor–based servers and examine how DAX units can help to accelerate query execution. Contact your Oracle representative or visit the resources listed below to learn more.
See Also
About the Authors
Larry McIntosh is the chief architect within the Oracle Optimized Solutions team. He has designed and implemented highly optimized computing, networking, and storage technologies for both Sun Microsystems and Oracle. McIntosh has over 40 years of experience in the computer, network, and storage industries and has been a software developer and consultant in the commercial, government, education, and research sectors and an information systems professor. He has directly contributed to the product development phases of Oracle Exadata Database Machine and various Oracle Optimized Solution architectures. His most recent contribution has been in the design, development, testing, and deployment of Oracle Optimized Solution for Secure Oracle Database.
Ken Kutzer is a team lead for Oracle Optimized Solution for Secure Oracle Database and Oracle Optimized Solution for Oracle Database as a Service. He is responsible for driving the strategy and efforts to help raise customer and market awareness for Oracle Optimized Solutions in these areas. Kutzer holds a Bachelor of Science degree in electrical engineering and has over 20 years of experience in the computer and storage industries.
Randal Sagrillo is a solutions architect for Oracle. He has over 35 years of IT experience and is an expert in storage and systems performance, most recently applying this expertise to next-generation data center architectures, integrated systems, and Oracle engineered systems. Sagrillo is also a frequent and well-attended speaker on database platform performance analysis and tuning and has spoken at several industry conferences including Oracle OpenWorld, Collaborate, Computer Measurements Group, and Storage Networking World. In his current role, he is responsible for solution architecture and development around Oracle Optimized Solutions. Before joining Oracle, he held a variety of leadership roles in product management, program management, and hardware/software product development engineering.
Follow us:
Blog | Facebook | Twitter | YouTube