First off, I appreciate the time you guys spend on answering questions in this forum, its quite gracious of you to offer support for non paying users!
Anyway, yesterday we had a production issue where 2 of the 3 servers in our replication group ran out of disk space because of BDB JE chewing through all of it in a sudden manner, and I have been looking for the cause for the past day and I don't think I"m making any progress
The setup is 1 static master, and 2 replicas. (the master uses the designated primary / node priorty system to ensure it is the only server that will ever be elected the master and the replicas won't ever become the master. This feels very hacky, but since we are using a proxy to direct write requests to a specific server, when this application was written a few years ago, I'm guessing they thought it would be better to just have a static master rather then set up a system to inform the proxy of which node currently is the master). We also have a couple of development instances that occasionally connect to the replication group to catch up, but these are not online 100% of the time and can go days/weeks without being connected to the group
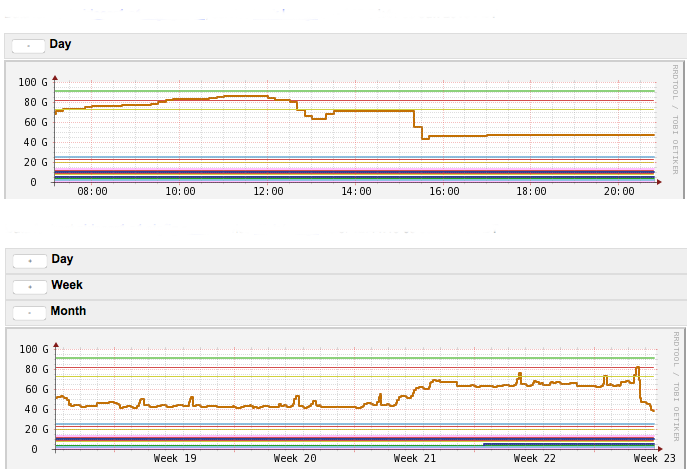
Looking at the graphs of disk usage over the past month (and year), i see that all of the servers disk usage for the BDB directory went up 20 gigs, at around may 25. Yesterday however, the replicas went up an additional 20 gigs, almost doubling in the size of the database and ran out of disk space. we don't add a lot of new data into the database per day, as evidenced by the year long disk usage graph, but on may 25th and yesterday the disk usage just shot out of control.
Even with the default values for replayCostPercent and replayFreeDiskPercent, both of the replica servers ended up running out of disk space. I ended up putting a je.properties file in the home directory with replayCostPercent = 0, and that seemed to help one of the replicas, but the other one dropped to the expected database size, and then shot up again. I ended up having to just delete the environment directory on the replica and having it restore itself via a NetworkRestore, and after that, the second replica seems relatively stable
A coworker suggested that maybe because of our development instances, the group might be holding on to extra data for replication to those instances, but I ended up removing those nodes using DbGroupAdmin, and it didn't seem to have an immediate effect. Looking into the BDB JE source code where those log messages are created, I have a hunch that maybe the global CBVLSN was dragged down by the development instances that were not online 100% of the time, and therefore all of the replicas and the master had to save extra data to support replicating to those?
I'm just confused on what exactly is happening here. Why were all the servers holding on to so much extra data, to the point that it would rather hold on to this data then prevent a "out of space" exception?
Looking in the je.info logs, i see a bunch of these:
(the second replica, the one I had to clear the environment directory)
in may i see a bunch of these:
2016-05-25 14:58:28.502 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa0284-0xa0299
2016-05-25 14:58:28.507 UTC INFO [slave-sidecar2] Replication prevents deletion of 22 files by the Cleaner to support replication using free space available beyond the 10% free space requirement specified by the ReplicationConfig.REPLAY_FREE_DISK_PERCENT parameters. Start file=0xa0284 holds CBVLSN 7,542,288,376, end file=0xa029b holds last VLSN 7,545,609,723
2016-05-25 14:58:28.507 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-05-25 14:58:28.508 UTC INFO [slave-sidecar2] Cleaner has 22 files not deleted because they are protected by replication. Files: 0xa0284-0xa0299
2016-05-25 15:00:07.099 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa0284-0xa0299
2016-05-25 15:00:07.104 UTC INFO [slave-sidecar2] Replication prevents deletion of 22 files by the Cleaner to support replication using free space available beyond the 10% free space requirement specified by the ReplicationConfig.REPLAY_FREE_DISK_PERCENT parameters. Start file=0xa0284 holds CBVLSN 7,542,288,376, end file=0xa029b holds last VLSN 7,545,662,859
2016-05-25 15:00:07.105 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-05-25 15:00:07.105 UTC INFO [slave-sidecar2] Cleaner has 22 files not deleted because they are protected by replication. Files: 0xa0284-0xa0299
2016-05-25 15:02:01.782 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa0284-0xa0299
2016-05-25 15:02:01.788 UTC INFO [slave-sidecar2] Replication prevents deletion of 22 files by the Cleaner to support replication using free space available beyond the 10% free space requirement specified by the ReplicationConfig.REPLAY_FREE_DISK_PERCENT parameters. Start file=0xa0284 holds CBVLSN 7,542,288,376, end file=0xa029b holds last VLSN 7,545,726,863
2016-05-25 15:02:01.788 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-05-25 15:02:01.788 UTC INFO [slave-sidecar2] Cleaner has 22 files not deleted because they are protected by replication. Files: 0xa0284-0xa0299
2016-05-25 15:03:37.099 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa0284-0xa0299
2016-05-25 15:03:37.105 UTC INFO [slave-sidecar2] Replication prevents deletion of 22 files by the Cleaner to support replication using free space available beyond the 10% free space requirement specified by the ReplicationConfig.REPLAY_FREE_DISK_PERCENT parameters. Start file=0xa0284 holds CBVLSN 7,542,288,376, end file=0xa029b holds last VLSN 7,545,781,504
2016-05-25 15:03:37.106 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-05-25 15:03:37.106 UTC INFO [slave-sidecar2] Cleaner has 22 files not deleted because they are protected by replication. Files: 0xa0284-0xa0299
---------------------------
then yesterday:
2016-06-08 23:39:44.609 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee
2016-06-08 23:39:44.610 UTC INFO [slave-sidecar2] Replication prevents deletion of 39 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5177 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03f9 holds last VLSN 7,687,374,471
2016-06-08 23:39:44.610 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-06-08 23:39:44.610 UTC INFO [slave-sidecar2] Cleaner has 39 files not deleted because they are protected by replication. Files: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee
2016-06-08 23:39:47.629 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:47.629 UTC INFO [slave-sidecar2] Replication prevents deletion of 40 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5177 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03f9 holds last VLSN 7,687,374,474
2016-06-08 23:39:47.629 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-06-08 23:39:47.629 UTC INFO [slave-sidecar2] Cleaner has 40 files not deleted because they are protected by replication. Files: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:51.243 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:51.243 UTC INFO [slave-sidecar2] Replication prevents deletion of 40 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5177 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03f9 holds last VLSN 7,687,374,474
2016-06-08 23:39:51.243 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-06-08 23:39:51.243 UTC INFO [slave-sidecar2] Cleaner has 40 files not deleted because they are protected by replication. Files: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:55.618 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:55.618 UTC INFO [slave-sidecar2] Replication prevents deletion of 40 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5232 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03fa holds last VLSN 7,687,374,479
2016-06-08 23:39:55.618 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-06-08 23:39:55.618 UTC INFO [slave-sidecar2] Cleaner has 40 files not deleted because they are protected by replication. Files: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:59.835 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:39:59.836 UTC INFO [slave-sidecar2] Replication prevents deletion of 40 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5232 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03fa holds last VLSN 7,687,374,482
2016-06-08 23:39:59.836 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
2016-06-08 23:39:59.836 UTC INFO [slave-sidecar2] Cleaner has 40 files not deleted because they are protected by replication. Files: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:40:03.366 UTC INFO [slave-sidecar2] Candidates for deletion: 0xa03c4-0xa03e2 0xa03e4-0xa03e8 0xa03ea-0xa03eb 0xa03ee-0xa03ef
2016-06-08 23:40:03.366 UTC INFO [slave-sidecar2] Replication prevents deletion of 40 files by the Cleaner to support replication by node master, last updated 2016-06-08 22:12:39.443 UTC, 5232 seconds before the most recently updated node, and less than the 86400 seconds timeout specified by the ReplicationConfig.REP_STREAM_TIMEOUT parameter. Start file=0xa03c4 holds CBVLSN 7,687,370,481, end file=0xa03fa holds last VLSN 7,687,374,485
2016-06-08 23:40:03.366 UTC INFO [slave-sidecar2] Files chosen for deletion by HA:
Here are the disk graphs for replica2. (It drops when i set replayCostPercent to 0, but then it jumps back up again. The stair stepping pattern is me clearing the environment directory and doing a network restore)
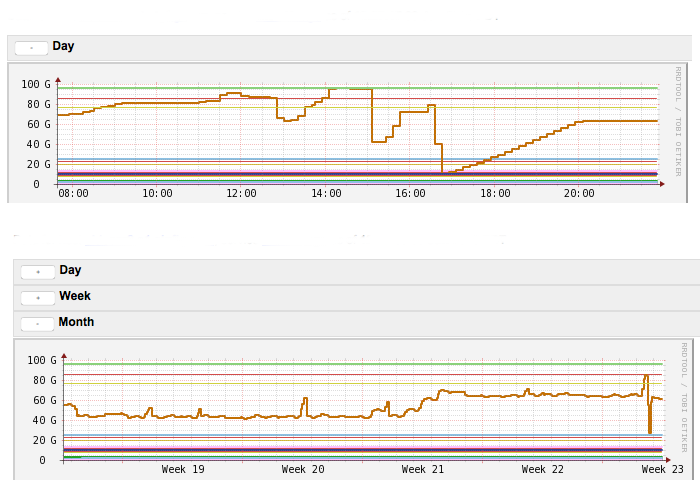
disk graph for replica1: (the drop seems to be correlated to when i set the replayCostPercent property to 0)