Hi,
Firstly I want to say that this is a very good extension, that gets me most of the way to moving away from SQL developer that I use everyday to write and run queries. It suffers a little from the usual Oracle lack of open-source and mystery around roadmaps (see the ROracle package as an example), but the forum is active enough to make up for that!
There are a few things, some of which I've seen are being worked on, that really stop it from moving me completely away from SQL Dev for all but the most power-user work. Hopefully this can offer as a collection of requests I've seen on the forum and others can add any others that they feel are relevant that I may have missed. I will also say I am not an expert so may have missed some ways to do these, but I can't see them obvious in the settings or any documentation (see mysterious Oracle comment).
- Easy proxy login - I managed to do it using the details on the forum, but it's still much more fiddly than using the user[schema] syntax of sql dev. I also tend to use a JDBC string rather than a TNS file which was another change I had to make, but not a huge impact.
- Object explorer of other schemas - This I see over and over again, I use it all the time because it is much cleaner than scrolling through select * from all_tables and the various other collections.
- Results pane location + overwrite - I may be doing it wrong, but I cannot get the results to default to a lower pane when they are first called, once the pane is open and moved it works, but I have to manually split the window then move it there first. This might be a limitation of VSCode that you can't for it, but it would be much better. I also am unable to keep multiple results open at the same time like I can either using the pin or (as I have it) setting this as the default in SQL dev. I often need to have tables I am working with open as references to check e.g. data formats or compare results. If it is possible to get these multiple results, then them also opening automatically in the bottom pane (once one is open) would be very useful.
- Better autocomplete in queries - To be honest, this has never worked great in the database I use in SQL Dev when compared to Toad anyway, any table name auto-completion actually works better in VScode, but column suggests are not smart at all. It just suggests all columns I have access to in the database, rather than at minimum just those on tables within the query or even better ideally those of the alias I am referencing at the time.
- Better filter in database explorer - Currently if you apply the filter it will match characters anywhere in e.g. a table name. We often use initials at the start of our table in a shared schema and the filter picks up any table that contain those letters anywhere, rather than matches containing that exact string. If this was regex or applied literal contains then I think it would be much more useful than the current format (although I am happy to be wrong here if there is a reason the current approach is better).
Quality of life things:
Less important, but would be good to see
- ctrl+e doesn't run a query when you're on an empty line but a valid query exists between the previous and next semi-colon. This is different to the default SQL Dev behaviour and feel ineffective in general.
- You have to use this package's syntax highlighting, which I find much less inclusive/useful than the other PL/SQL (Oracle) package available. You only use the same colour for any keyword or function, as where the other offers some divergence which can help make reading
code a little clearer. Compare the two in this simple case:
PL/SQL (Oracle)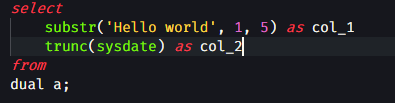 Oracle-SQL and PLSQL:
Oracle-SQL and PLSQL: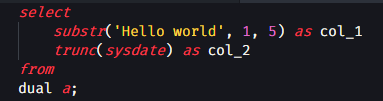
- Cached intellisense data; we have quite a large database so having to refresh this on every connect can take about a 5-10 minutes sometimes, it would be beneficial if this could be cached somewhere to save having to do this every time and just get coding quicker. The only reason this is QoL rather than essential is because until there is smarter column autocomplete this is limited in it's value anyway.
- Copy customisation; it would be great to have the option to copy without all values being quoted, and sometimes without a header as well. Just the option to toggle these on/off in the results pane would be great. Other than that I think the results pane and the copy feature are genuinely fantastic.
Hopefully this list is helpful, and with some luck some of these are already in development for the extension or are possible and I just can't work out how. As I said I do really like this extension, but there's just a few too many things holding it back for me to fully make the switch yet, no matter how much I want to.
Thanks,