by Vijay Tatkar
The SPARC M7 Data Analytics Accelerator is a unique innovation that accelerates a broad base of industry-leading analytic applications.
With the release of its 32-core, 256-thread SPARC M7 processor, Oracle provides a number of Software in Silicon (SWiS) innovations that build higher-level software functions into the processor's design. One of the most exciting innovations is the Data Analytics Accelerator (DAX) coprocessor, which delivers unprecedented analytics efficiency. DAX is a specialized set of instructions that can run very selective functions—Scan, Extract, Select, and Translate—at blindingly fast speeds. Additionally, DAX can also decompress, at memory speeds as high as 120 Gb/second, data stored by in-memory applications, thereby increasing memory capacity.
Read in greater detail about Software in Silicon features here.
The introduction of these functions is a novel approach to chip design, reminiscent of how floating point instructions were introduced in the 1980s. DAX instructions were originally intended to speed up Oracle Database, and they are indeed used in Oracle Database In-Memory in Oracle Database 12_c_ to run SQL queries in parallel on millions of elements at once yielding unbelievable query rates of 170 billion rows/second. However, they can apply equally well in the analytic world of big data and machine learning, where similar core functions can be greatly accelerated.
Real-world analytics requires continuous iterative exploration and investigation of business data and needs to run many simultaneous queries against the database. The SPARC M7 processor was designed with 32 cores and 32 DAX query engines, to exploit this parallelism. In addition, DAX units minimize cache usage and run independent of the processor cores. Thus, it is now possible to run queries in the DAX query engines while running business logic in parallel on the processor's S4 cores, which is a significant breakthrough. Additionally, the DAX engines also decompress compressed data on the fly, which means it can scan compressed data directly (instead of performing the tedious operation of decompressing the data, writing it back into memory and then reloading the decompressed data back into the processor for running a scan operation). Functionally, this decompression performance is equivalent to having an additional 64 normal cores, and the DAX query engines are equivalent to having 32 additional cores. Moreover, such decompression speeds mean increased usable memory capacity, by enabling compressed data to be stored in memory and manipulating it at full speed.
How Does It Work?
It helps to take a look at the chip layout, which is shown in Figure 1.
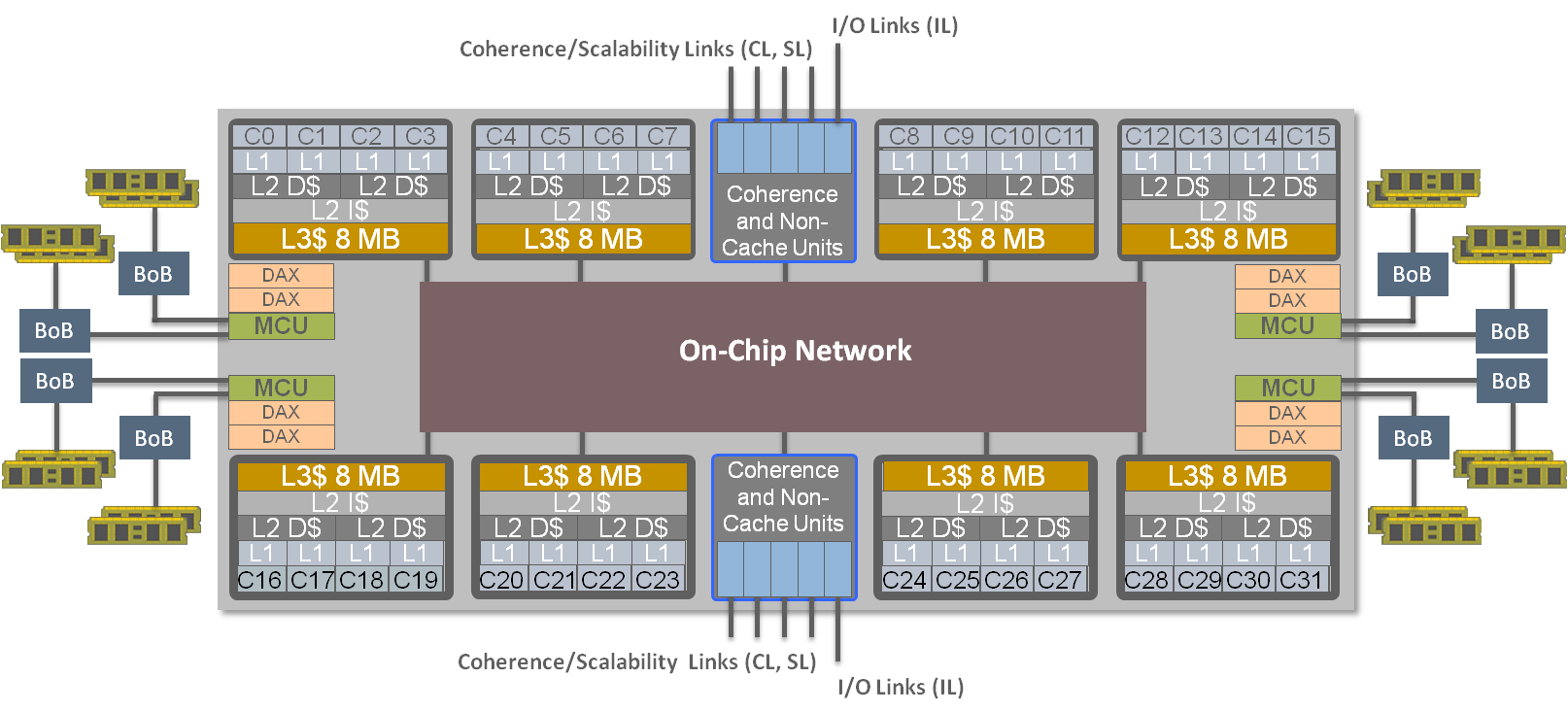
Figure 1. DAX units are located near the memory controller units
There are 32 compute cores, in 8 core clusters at the top and bottom of the chip. The middle part of the chip is where various caches are located, as well as the on-chip network. The eight DAX units are on the two ends and lie between the memory controller units (MCUs) and the caches. Therefore, the DAX units can easily communicate with both and not pollute the caches during operations. Each DAX unit has four threads, making a total of 32 DAX query engines on every chip (this internal detail is not shown in the layout). Any of SPARC M7 cores can access any DAX unit. When a processor core requests help from a DAX unit, the core is provided only with the results of the operation that are needed.
The details of the operation within the DAX units are shown in Figure 2.
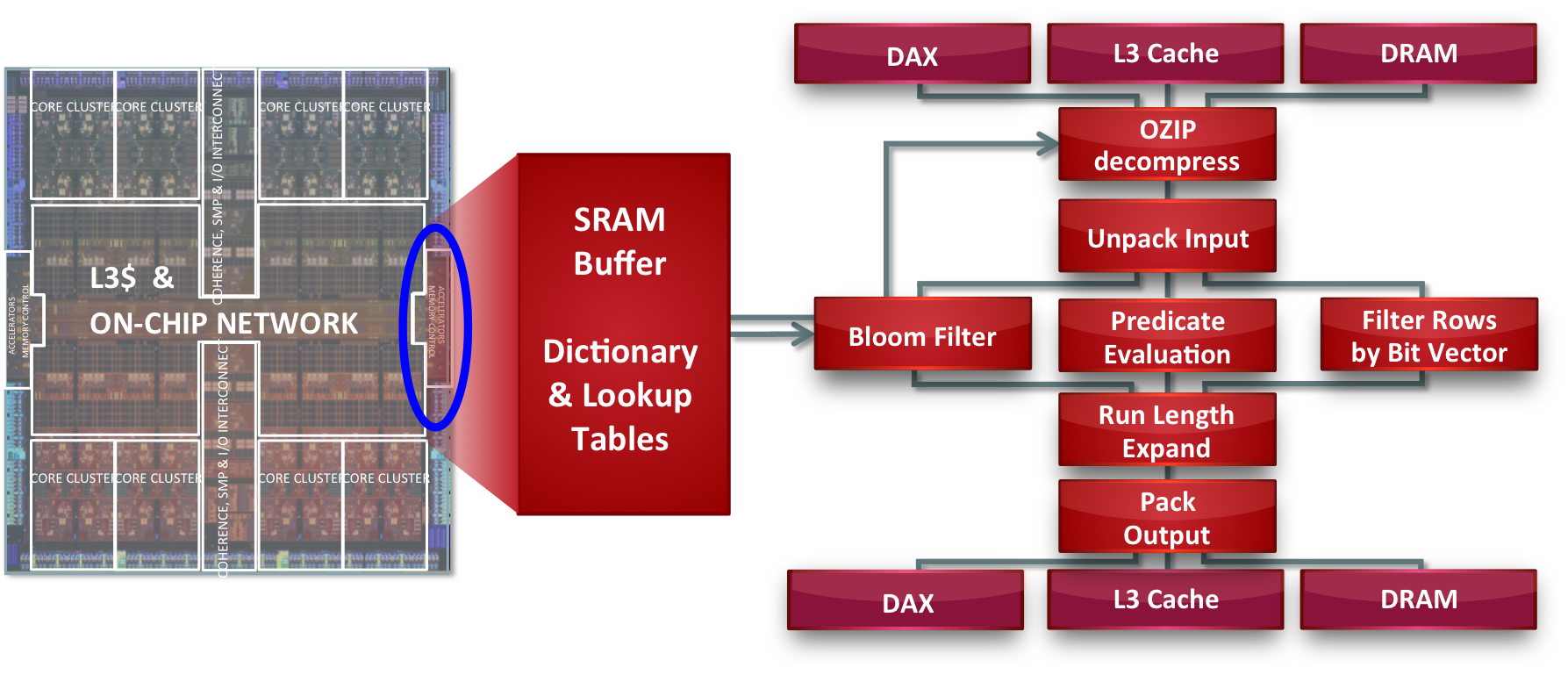
Figure 2. Pipeline stages within DAX units
On the left, each DAX unit has a high-speed SRAM buffer where it keeps data that it needs to access quickly, such as a decompression dictionary and lookup tables. On the right, each unit can get input from another DAX unit, thus pipelining instructions; or from the L3 cache, which is how it communicates with the cores; or from DRAM memory. Because the DAX units are placed with the MCUs, they can get data at full memory speed. Data coming in is pipelined through a number of stages.
- The first is decompression. The decompression units understand the Oracle Ozip format.
- Uncompressed data is then unpacked through an operation called Extract. Data might need to be expanded into full words if the data is byte- or bit-packed or run-length encoded.
- The next stage of the pipeline performs joins (called Bloom Filter); evaluates conditions (predicates) such as less than, greater than, or equal to; or performs matches based on an existing result of bit vectors.
- In the next stage, the resulting data is expanded via repeating decompressions.
- Then the output is packed (if it was expanded or unpacked initially) back into the compact format it was originally in. Just as there are three input sources, the output can also be pipelined either into another DAX unit, into the L3 cache, or back into DRAM memory.
This is a very specialized pipeline and can process data at memory speeds, because it chunks through each stage on every clock tick. All this processing, equivalent to having 32 extra cores for queries and 64 extra cores for decompression, actually takes up very little space on the processor, making it very cost effective.
With competitor (and previous Oracle processor) designs, such operations are translated into specialized vector single-instruction multiple-data (SIMD) operations (such as instructions for database operations). These operations transfer all data into a processor's core, filling the caches and pushing out previously relevant data, thereby "polluting" the caches by victimizing (pushing out) existing cache content. Moreover, these operations follow a different, more conventional and less efficient pipeline than the one shown in Figure 2. Worse, vectorization on other architectures can handle significantly smaller memory chunks, often 256 or 512 bits, whereas on the SPARC M7 chip, the DAX units can stream in data in several megabyte chunks. Thus, the DAX design cuts down on processor data transfers, conserves cache relevancy, and ensures that processor cores are free from very simplistic tasks such as searching for a bit pattern in memory. DAX tasks are offloaded from the processor cores, so the cores can simultaneously work on other tasks.
DAX units perform four basic tasks:
1. Extract: Create an unpacked output stream from an input stream that may be any of the following:
- Fixed-width byte-packed
- Fixed-width bit-packed
- Run-length encoded (RLE)
- N-gram Huffman–compressed
- Variable-width byte-packed
2. Scan: Compare the elements of an input vector to two or more boundary values.
3. Select: Given an input data vector and an input bit vector, produce an output vector element that matches the input bit vector.
4. Translate: Transform an input source vector—using a bit-vector translate table pattern—into corresponding bits at those indices.
To summarize, some of the important SPARC M7 and DAX design advantages are
- Industry-leading memory bandwidth. Analytics performance is often limited by how quickly large amounts of in-memory data can be accessed. At an industry-leading 160 Gb/sec memory bandwidth, the SPARC M7 processor provides enough capacity to feed both the DAX units as well as the processor cores.
- DAX offload. As stated earlier, freeing the processors cores for other processing tasks is a huge benefit.
- Efficient decompression combined with in-memory processing. Putting decompression in the DAX units is much faster than using software implementations, and designing decompression with scanning means needless back-and-forth memory transfers are avoided. Results from the DAX units are put directly into the CPU cache for better CPU efficiency.
- DAX range comparisons. Many real-world database analytics queries are written to find data transacted between certain dates, between certain product-cost ranges, and so on. The DAX units process range comparisons at the same rate as individual comparisons. Other processors require additional computational time for each comparison.
- Avoiding cache pollution. The DAX units do much of their computation without the need to store intermediate data in a cache, which frees the CPU's cache for other processing tasks.
How Can DAX Be Used?
These advantages can be exploited in several algorithms. Here are some examples:
- Dealing with key value pairs, both simple and complex
- Building analytic cubes
- Finding the top <N> items from an ordered list
- Performing in-memory merged sorts
- JavaScript Object Notation (JSON) processing
- Outlier detection
These operations are used in popular big data and machine learning algorithms. One example of this type of usage is an implementation of Apache Spark in an application we created that builds cubes. In a traditional implementation, to build a cube, each point has to be traversed once and assigned to a specific cell. With the SCAN function, which can filter more than a million integers in one instruction, all the values can be scanned in, one dimension at a time. With the distributed computing framework of Apache Spark, this approach is further beneficial because all the Java Virtual Machines (JVMs) and threads of our application can use the DAX functionality. This speeds up the cube building process by up to 6 times compared to the traditional implementation. See a detailed description of this here.
Besides Apache Spark, which is popular in machine learning applications, DAX technology can be used for other popular types of algorithms, some of which are listed here:
- Process and discover patterns
- Fraud and intrusion detection
- Risk-based authentication
- Recommendations on buying patterns or new trends
- K-means clustering for machine learning and data mining
- K-nearest neighbor (KNN) for classification and regression
This list is not exhaustive. DAX technology can be applied fairly broadly. If the algorithm fits the schema outlined here, the performance improvement can be orders of magnitude higher.
See Also
About the Author
Vijay Tatkar is director of Oracle's ISV Engineering group and has over 27 years of experience at Sun and Oracle. Currently, his worldwide team works with ISVs to drive adoption and integration of Oracle systems technologies to build a strong ecosystem for Oracle Solaris and SPARC platforms. ISV Engineering collaborates with partners by defining joint roadmaps and engineering projects that create compelling, differentiated solutions. Tatkar also leads the Open API DAX engineering initiative. Prior to joining ISV Engineering, he managed the development of compilers, the Oracle Solaris Studio Performance Analyzer and Code Analyzer tools, and the cloud computing initiative at Sun.
| Revision 1.0, 03/02/2016 |
Follow us:
Blog | Facebook | Twitter | YouTube