by Suman Somasundar
Apache Spark's in-memory framework is an ideal showcase for seeing the acceleration benefits of the Data Analytics Accelerator (DAX), one of the Software in Silicon innovations in Oracle's SPARC M7 processor.
About Apache Spark
Apache Spark is an open source cluster computing framework, originally developed in AMPLab at the University of California, Berkeley, but later donated to the Apache Software Foundation. Compared to Hadoop's two-stage disk-based MapReduce paradigm, Spark's in-memory primitives provide performance up to 100x faster for certain applications. The framework abstracts the input data in the form of Resilient Distributed Datasets (RDDs). These RDDs can be created from an object in the program or they can be created directly from a text file. The two methods—parallelize() and textfile()—can be called with the Spark context object to create the RDDs. RDDs are immutable, which means any changes to an RDD creates a new RDD. They reside in memory, thereby reducing disk traffic for intermediate results. This helps Spark achieve a speed that is up to 100x faster compared to Hadoop-2.x for some applications.
Spark has a driver program that manages the entire operation. This program distributes the work to be done to a number of processes (Java Virtual Machines [JVMs]) called executors. Each executor has a number of worker threads. This architecture helps Spark achieve a high degree of parallelism.
Two types of operations are supported by RDDs:
- Transformations. These operations create a new RDD by modifying an existing RDD. Examples include
map, filter, groupByKey, and so on.
- Actions. These operations return a value to the driver program after running computations on the RDDs. Examples include
count, reduce, and so on.
Generally, Spark applications have the following stages.
- Read the input data and create an RDD—The data can be read in the driver program and an RDD can be created from this object in memory using the
parallelize() API. An RDD can be created directly from files using the textfile() API, where the contents of the files are read in the executor.
- Transformation—A number of transformations are applied on the RDD(s) to make changes to the input data and bring them to the required format.
- Action—The final result (usually some aggregation) is collected in the driver program.
Prerequisites for Running Spark with DAX
The applications that benefit most from DAX are applications that sort data and search unsorted data, which both involve lot of memory scans. Not all Spark applications would benefit from using DAX. Some examples of applications that would not benefit are applications that perform matrix multiplication or applications in which the input data is modified many times.
To begin, it is beneficial to start with a standalone Java program that uses the DAX APIs. This will help identify data that is a candidate to be converted to in-memory DAX objects.
Developing Spark Applications Using DAX
The Java program has to be rewritten in Spark style, which consists of a series of transformations of input data and an action at the end to collect the final result. We have sample code to show how input data can be mapped to Spark RDDs. The next step would be to create map, filter or other transformations on the RDDs based on the logic of the original Java program. At the end, the result is collected from the RDDs in the last stage using action APIs such as count, collect, and so on.
About DAX
Each SPARC M7 chip has 32 powerful DAX coprocessor engines designed to dramatically speed up in-memory calculations and offload processing, thus freeing the cores for other processing. These DAX units have the ability to decompress in-memory data and scan it without using additional memory bandwidth. While this is an ideal scenario for running SQL queries on a very large database column, the inherent mechanism can be used to speed up a number of other operations as well. DAX processing units can stream data at full memory bandwidth, and this processing runs in parallel while the cores execute other instructions. Figure 1 is a block diagram of the SPARC M7 processor showing the DAX units:
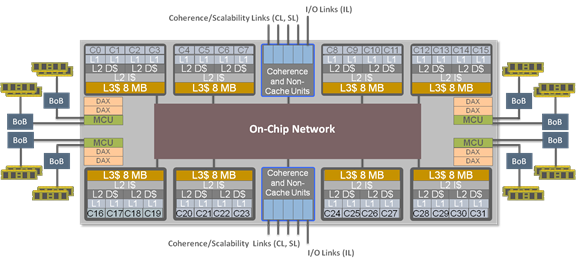
Figure 1. Block diagram of SPARC M7 chip and DAX units
DAX units have powerful features, such as Select, Scan, Translate, and Extract, which are great to use with Apache Spark to highlight the performance difference of using versus not using DAX technology. We have chosen a simple, but widely used, application to demonstrate the benefits of DAX functionalities—building a cube.
The input data is a million points in three-dimensional (3-D) space, and the values in each dimension range from 1 to 100. Our application groups all the points inside a boundary in the 3-D space into a cell. This cell contains the total number of points inside the particular boundary.
In a traditional implementation, to build the cube, each point has to be traversed once and assigned to a specific cell. With the SCAN function, which can filter more than a million integers in one instruction, we scan all values in one dimension at a time. A distributed computing framework such as Apache Spark is further beneficial because all the JVMs and threads of the application can use this functionality. This speeds up the cube building process by up to 6 times compared to the traditional implementation.
The DAX functionality used in our project is made available by a Vector library built on top of the libdax library. The libdax library provides APIs that translate the basic functionality of the DAX units; the Vector library provides a solver layer that abstracts the stream into a vector and performs logical operations on them. Both these APIs are provided for developers. These APIs provide functionality to read data from a comma-separated values (CSV) file or a JSON file and convert the data to the format required by the DAX units, do the SCAN operation on the DAX units, and so on.
Building the Cube
In our application, we use parallelize() to create an RDD from the input data, and then we use successive map transformations to modify the RDD to build the cube. In the end, we use the collect() action to display the result.
Inside the user-defined map function, we use the following functions provided by the Vector library.
vectorLoadFromArray: This function creates a vector from the input array in the format required for DAX operations.vectorFilter: This function scans the vector and returns a bit vector that has value 1 in the corresponding places where the value of the vector is inside a specified range.bitVectorAnd2: This function performs an AND operation on two bit vectors and returns a bit vector whose value is 1 in the corresponding places where both the original bit vectors have a value of 1.bitVectorCount: This function returns the number of 1s in the bit vector.vectorDestroy: This function destroys the vector.
To start with, we read the input data from the CSV file in the driver JVM to store it in a two-dimensional array. The columns of this two-dimensional array (values corresponding to 1 in a particular dimension) are added as separate elements to an arraylist. By passing this arraylist as an argument for parallelize() function, an RDD of the input data is created in which each element is an array of all values of a particular dimension.
Then, a map operation is applied on this RDD, which creates a vector from the input data in the required format for the DAX SCAN operation. Then, the SCAN operation is applied on the input data with different scan ranges. We get 30 bit vectors as output from this operation: 10 bit vectors each for of the three dimensions. These 10 bit vectors from each dimension are then combined in all possible ways to form the one thousand cells of the cube. A second map operation is applied to perform an AND operation on this bit-vector RDD and the 3-bit vector for each cell. Then, a count of the number of 1s in the bit vector is stored as the value of the cell.
Parallelization is achieved by using multiple threads in one executor. Being part of same executor allows threads to share data.
With the current implementation, the first map operation can be parallelized into up to three mapper threads, each working on data corresponding to one dimension. The second map operation can be parallelized, theoretically, into up to one thousand mappers, each working on the data corresponding to one cell. In practice, approximately 20 mappers give optimal performance; beyond this, the amount of work per thread is too little to justify the overhead of thread creation.
Note: You can access the working Java code for building the cube on Spark with a DAX implementation at http://swisdev.oracle.com/DAX/ (requires registration). Inside your project, you can create a special DAX zone from a template that has been provided, and which contains all the source code examples.
Key Findings
Figure 2 and Table 1 illustrate the main findings, which show that using Spark with the DAX units was 6x faster than not using the DAX units.
- Data processed by one thread is accessible by another thread in a different stage.
- Because different stages are carried out in the same JVM but with different threads, the startup time is reduced.
- This parallelization is possible with one executor only, but with multiple threads.
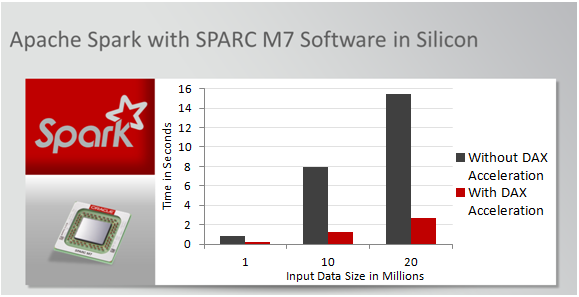
Figure 2. Using Spark with or without the SPARC M7 DAX units to build a 10*10*10 cube
Table 1. Time it takes to build the cube using Spark with or without the SPARC M7 DAX units
|
Integer Cube Building with and without DAX
|
| Data size |
1 M
|
10 M
|
20 M
|
| Build type | DAX | Non-DAX | DAX | Non-DAX | DAX | Non-DAX |
| Time it takes to create 10 * 10 * 10
cube (in seconds) | 0.209 | 0.884 | 1.279 | 7.895 | 2.690 | 15.465 |
See Also
About the Author
Suman Somasundar graduated from Cornell University with a master's degree in computer science. He joined Oracle in March 2014 and started working on various big data technologies, initially on the Apache Mahout machine-learning library. His main focus for the last two years has been on optimizing open source big data technologies for Oracle Solaris/SPARC. More recently, he has been working to make Apache Spark and Spark MLlib use DAX on Oracle's SPARC M7 processor.
Follow us:
Blog | Facebook | Twitter | YouTube