by Greg Jumper and Kumaraswamy
Learn how to increase the speed of your analytic applications by using the Data Analytics Accelerator (DAX) API and DAX coprocessors.
In March 2016, Oracle introduced the DAX API library, which enables you to create high-performance applications that can process and analyze large amounts of data effectively. The DAX API allows you to use stream-processing techniques to efficiently manipulate large amounts of data in memory, by taking advantage of the hardware acceleration that is available on Oracle's latest SPARC microprocessors. The volume of data stored in databases is growing exponentially and the need to analyze these large volumes of data in real time to run a variety of reports is a pressing reality of the times. Analytic applications need to access, decompress, and run fast queries on the stored data. You can significantly increase the speed of your analytic applications by using the DAX API. DAX-enabled applications can run on any SPARC system. However, the latest generation of SPARC M7 and SPARC S7 processor–based servers from Oracle include DAX coprocessors that are able to run analytic applications even faster by offloading analytic functions onto the DAX coprocessors.
What Is the DAX API Library?
The large memory capabilities of today's server systems enable very efficient manipulation of large data sets. Stream-processing techniques allow efficient use of system resources by structuring memory operations as regular patterns that can be accelerated by the DAX coprocessors. The DAX API provides a rich set of stream-processing operations that allow you to take advantage of the hardware acceleration on Oracle's latest SPARC systems. The DAX API supports the following operations on data that is streamed to and from memory:
- Extract: Decompresses or unpacks a data stream. The output of this operation is a stream of elements.
- Scan Value: Identifies the input elements that match a particular value. The output of this operation is a bit vector or an array of indices.
- Scan Range: Identifies the input elements between boundary values. The output of this operation is a bit vector or an array of indices.
- Select: Selects a specific subset from the input elements. The output of this operation is a stream of elements.
- Translate: Maps input indices to the values of a table at those indices. The output of this operation is a bit vector or an array of indices.
- Compress: Compresses a stream of input elements and writes the compressed data to an output buffer.
- Logic: Performs logical operations.
The DAX API operates on data as it is loaded from memory without incurring additional latency.
Extract Operation
The Extract operation unpacks and, if required, decompresses a data stream to produce a padded-byte output stream.
A data stream can be both packed and compressed at the same time. Packing eliminates unnecessary space in a data stream, and compression replaces a verbose data stream with a more-compact equivalent that contains the same information. The compression format can be run-length encoding (RLE), zip, or both. Table 1 shows how the DAX API supports the input formats with optional RLE and zip compression.
Table 1. Library support for input formats
| Input Format | RLE Compression Supported? | Zip Compression Supported? | Both RLE and Zip Compression Supported? |
| Fixed-width, byte-packed | yes | yes | yes |
| Fixed-width, bit-packed | yes | yes | yes |
| Variable-width, byte-packed | no | yes | no |
To extract variable-width or RLE data, you must provide an additional data stream that specifies the sizes of the elements in the input data stream. Similarly, to extract zip-compressed data, you must provide a codec.
For example, you can pack the four 4-bit symbols 1111, 0000, 1010, and 0101 into a 2-byte stream:
11110000 10100101
The DAX API can unpack the 2-byte stream as four padded bytes:
00001111 00000000 00001010 00000101
The unpacked bytes can be operated on directly without the need to shift and mask bits to access the subfields of the bytes.
In this example, suppose the packed data stream is compressed by using the RLE or zip methods. The DAX API can decompress and unpack the packed data in a single operation.
Scan Value Operation
The Scan Value operation compares each element in the input data stream with a user-supplied value. If the comparison is true, the corresponding bit in the output bit vector is set to 1; otherwise, it is set to 0, for example:
If InputDataStream[i] == VALUE OutputBitVector[i] = 1 Else OutputBitVector[i] = 0
The example in Table 2 shows the bit vector output values from a Scan Value operation.
Table 2. Example bit vector output values from Scan Value operation
| Input Elements | User-Supplied Value | Output Bit Vector |
| 1,2,3,4,5 | 3 | 00100 |
The Scan Value operation can accept a run-length encoded (RLE) input stream in which each data element is implicitly repeated a number of times. A per-element repeat count is read from a secondary input stream. The DAX coprocessors concurrently read the input streams, replicate each element, perform the comparison operation, and write the result to the output stream. RLE is an effective data compression technique when consecutive data elements commonly have the same value, such as in a sorted stream with duplicates allowed. You can use it to reduce the memory required to store the input stream, with no loss of performance at query time. For example, if the original data stream is this:
Data = 8,8,8,5,5,8,8,8,8,7
The RLE representation is this:
Input Elements = 8, 5, 8, 7
Repeat Counts = 3, 2, 4, 1
The example in Table 3 shows the bit vector output from a Scan Value operation with RLE input.
Table 3. Example bit vector output values from Scan Value operation with RLE input
| Input Elements | Repeat Counts | User-Supplied Value | Output Bit Vector |
| 8, 5, 8, 7 | 3, 2, 4, 1 | 8 | 1110011110 |
The Scan Value operation can accept a DAX-specific zip-compressed input stream. You compress the data using the Compress operation and pass the compressed stream and its decoder to the DAX coprocessors. The DAX coprocessors concurrently decompress the data, partition the unzipped stream into data elements, and scan the elements. Zip is an effective data compression technique for a broad range of input data distributions, but it requires more CPU time to compress the data than RLE requires.
The decoder contains up to 1024 symbols of 1 to 8 bytes each, with some constraints that are not covered here. The compressed stream consists of a sequence of codewords, where a codeword is an index into the symbol table.
For example, suppose the original data stream has the following 4-bit elements, in hexadecimal:
Data = 3, 2, 5, 2, 5, 2, 0, 0, 0, 0
Also supposed that the decoder shown in Table 4 is used.
Table 4. Example decoder
| Codeword (2 Bits) | Symbol | Length (Bytes) |
| 0 | 0x32 | 1 |
| 1 | 0x52 0x52 | 2 |
| 2 | 0x00 | 1 |
The zipped representation is the following:
Codewords = 0, 1, 2, 2
And the bit vector output from a Scan Value operation is shown in Table 5.
Table 5. Example bit vector output from Scan Value operation
| Codewords | Decoder | User-Supplied Value | Output Bit Vector |
| 5,8,6,8,8 | Contains up to 1,024 symbols of 1 to 8 bytes each | 0x5 | 0010100000 |
The Scan Value operation can also output the index of the input element where the comparison result is 1. The index is written as a 2- or 4-byte big-endian word.
The example in Table 6 shows the ones-index output from a Scan Value operation.
Table 6. Example ones-index output values from Scan Value operation
| Input Elements | User-Supplied Value | Ones-Index Output |
| 5,8,6,8,8 | 8 | 1,3,4 |
This operation supports the following comparisons:
InputDataStream[i] == VALUEInputDataStream[i] != VALUEInputDataStream[i] < VALUEInputDataStream[i] <= VALUEInputDataStream[i] > VALUEInputDataStream[i] >= VALUE
Scan Range Operation
The Scan Range operation compares each element in the input data stream with a range of values defined by a lower and an upper value. If the comparison is true, it outputs 1. It outputs 0 otherwise, for example:
If MIN_BOUND_VAL <= InputDataStream[i] <= MAX_BOUND_VAL OutputBitVector[i] = 1 Else OutputBitVector[i] = 0
The example in Table 7 shows the output values from a Scan Range operation.
Table 7. Example output values from Scan Range operation
| Input Elements | User-Supplied Minimum and Maximum Values | Output Bit Vector |
| 1,2,3,4,5 | 2,4 | 01110 |
Similar to the Scan Value operation, the Scan Range operation can output the index of the input element where the comparison result is 1. The index is written as a 2- or 4-byte big-endian word.
This operation supports the following comparisons:
MIN_BOUND_VAL <= InputDataStream[i] && InputDataStream[i] <= MAX_BOUND_VALMIN_BOUND_VAL <= InputDataStream[i] && InputDataStream[i] < MAX_BOUND_VALMIN_BOUND_VAL < InputDataStream[i] && InputDataStream[i] <= MAX_BOUND_VALMIN_BOUND_VAL < InputDataStream[i] && InputDataStream[i] < MAX_BOUND_VALMIN_BOUND_VAL != InputDataStream[i] && InputDataStream[i] != MAX_BOUND_VALMIN_BOUND_VAL == InputDataStream[i] || InputDataStream[i] == MAX_BOUND_VALInputDataStream[i] < MIN_BOUND_VAL || InputDataStream[i] >= MAX_BOUND_VALInputDataStream[i] <= MIN_BOUND_VAL || InputDataStream[i] >= MAX_BOUND_VALInputDataStream[i] < MIN_BOUND_VAL || InputDataStream[i] > MAX_BOUND_VALInputDataStream[i] <= MIN_BOUND_VAL || InputDataStream[i] > MAX_BOUND_VAL
Select Operation
The Select operation checks each element in the input data stream and outputs the element if and only if the bit at the corresponding location in a user-supplied bit vector is 1, for example:
Output InputDataStream[i] if and only if BitVector[i] == 1
The example in Table 8 shows the output values from a Select operation.
Table 8. Example output values from Select operation
| Input Elements | User-Supplied Bit Vector | Output Data Stream |
| 1,2,3,4,5 | 10101 | 1,3,5 |
Translate Operation
The Translate operation outputs the values of a user-supplied "translate table," which is a bit vector. The index values of the translate table would be the elements of the input data stream. The DAX API interprets the input data stream as a stream of zero-based indices, for example:
OutputBitVector[i] = TranslateTable[InputDataStream[i]]
The Translate operation can also produce an inverted output, for example:
InvertedOutputBitVector[i] = NOT(TranslateTable[InputDataStream[i]])
The example in Table 9 shows the output values from a Translate operation.
Table 9. Example output values from Translate operation
| Input Elements | Translate Table | Output Bit Vector |
| 7,3,1,5 | 010101010 | 1111 |
The Translate operation can also output the index of the input element where the translation result is 1. The index is written as a 2- or 4-byte big-endian word.
The example in Table 10 shows the ones-index output from a Translate operation.
Table 10. Example ones-index output values from Translate operation
| Input Elements | Translate Table | Ones-Index Output |
| 5,6,7,8 | 010101010 | 0, 2 |
Compress Operation
The compress operation zips the data in the input data stream and writes the codeword stream to the output buffer. The output buffer is a contiguous stream of fixed-width codewords with no padding between each. The codec provides the width of the codeword, which can be 1 to 10 bits wide, and each codeword is big endian. This operation returns an encoder or decoder that you can use to unzip the data.
The DAX hardware does not compress the data. Compression is implemented in software.
Logic Operations
The DAX API performs logical operations such as AND, OR, and XOR on the input and output vectors.
The DAX hardware does not perform the logical operations. The functions that perform logical operations are implemented in software.
DAX Coprocessors on the SPARC M7 and SPARC S7 Processors
The DAX coprocessors available on the SPARC M7 and SPARC S7 processors enable direct execution of many of the DAX API operations, manipulating in-memory data streams directly and freeing the SPARC CPU for other tasks. A single SPARC M7 or SPARC S7 processor has eight DAX "units" or coprocessors. The eight DAX coprocessors perform stream processing of either compressed or uncompressed data. Because the DAX coprocessors process the query independently from the core processor, the processor cores are free to process other instructions. DAX coprocessors speed up the in-memory query execution and place the results in the shared L3 cache for fast core access. Hence, they provide significant performance improvements for in-memory analytics.
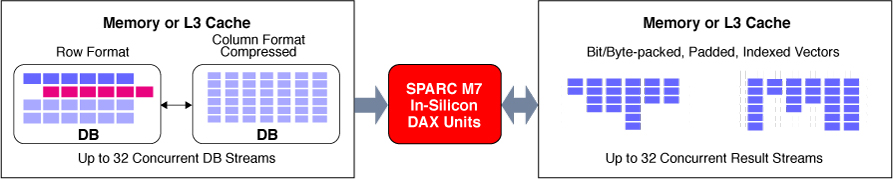
Figure 1. DAX processing on the SPARC M7 processor
Apart from the DAX coprocessors, the SPARC M7 and SPARC S7 processors also have in-chip Silicon Secured Memory enhancements and crypto instruction accelerators.
Oracle Database In-Memory
Oracle Database 12_c_ supports the Oracle Database In-Memory option, and the SPARC M7 and SPARC S7 chips have DAX coprocessors. By using both Oracle Database In-Memory and the DAX coprocessors to execute your data queries, you can achieve significant performance improvements in your analytic applications.
Traditionally, Oracle Database stores data in a row format. In a row format, each new record is represented as a new row in the table. Each row comprises multiple columns and all the columns for the row are stored in contiguous database blocks. Data stored in a row format is ideal for online transaction processing (OLTP) because it allows quick access to all the columns in a record.
However, in certain cases, such as analytics and report generation, it is advantageous to store the data in a column format. In a column format, Oracle Database In-Memory stores each of the attributes about a transaction or record in a separate column structure. This is ideal for analytics and report generation because it allows for faster data retrieval when a query selects only a few columns from a large data set.
Figure 2 shows how Oracle Database In-Memory provides a dual-format architecture that uses row format for OLTP operations and column format for analytic operations.
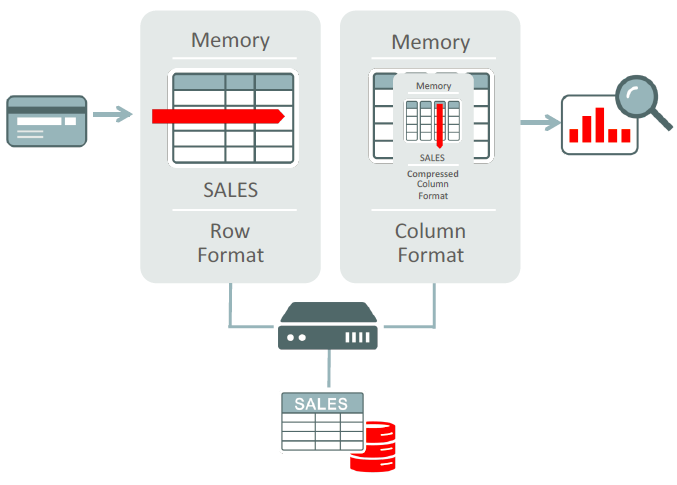
Figure 2. Processing with Oracle Database In-Memory
The simple database shown in Table 11 has 4 rows and 3 columns.
Table 11. Simple database example
| ID | Product | Selling Price |
| 1 | Product1 | 500 |
| 2 | Product2 | 450 |
| 3 | Product3 | 550 |
| 4 | Product4 | 300 |
In a row format, the data in Table 11 would be stored as follows:
1,Product1,500;2,Product2,450;3,Product3,550;4,Product4,300;
However, in a column format, the data in Table 11 would be stored as this:
1,2,3,4;Product1,Product2,Product3,Product4;500,450,550,300;
With data manipulation language (DML) operations—such as insert, update, or delete—a row format is very efficient because it manipulates an entire record in one operation. A column format is not so efficient at processing row-wise DML operations, because to insert or delete a single record in a column format, all the columnar structures in the table must be updated.
Oracle Database In-Memory provides the benefits of both the row and column formats. It supports dual formats in memory: rows for transactions and columns for analytics. For a technical description of how Oracle uses this functionality in Oracle Database, please refer to the "Oracle Database In-Memory: A Dual Format In-Memory Database" publication from the proceedings of the IEEE International Conference on Data Engineering (ICDE), 2015.
Try It Yourself
You can access Oracle's Software in Silicon technology by registering at the SwisDev website, which offers free development and test environments as well as sample use cases. To access the DAX API and test how it can speed up your analytics applications, register at swisdev.oracle.com/DAX. To test all other Software in Silicon features, such as Silicon Secured Memory, register at swisdev.oracle.com.
Conclusion
In Oracle Database 12_c_, SQL query processing is optimized to use the DAX API to improve query performance significantly. Additional sample programs have been developed to illustrate the use of the DAX API. The DAX API will continue to evolve over time as more applications are developed and more analytic functions are added.
About the Authors
Greg Jumper is a principal software engineer in the Oracle's SPARC/Oracle Solaris organization with over 18 years of experience at Sun Microsystems and Oracle. He led development of the Oracle Solaris software for SPARC M7 DAX support and works on software projects to support new SPARC platforms and to further integrate Oracle Solaris with Oracle Database.
Kumaraswamy is a principal technical writer in the Oracle's Solaris organization with over 10 years of experience at Sun Microsystems and Oracle. He works on creating developer-related content and handles the developer documentation for Oracle Solaris.
| Revision 1.1, 06/29/2016 |