by Karthik Ganesan
This article introduces a technology engineered to streamline Java analytics using hardware acceleration, which results in extreme performance while using drastically fewer compute resources.
Most Java applications today use collections, allowing the grouping and processing of a large amount of data efficiently in a programmer friendly manner. The Java Virtual Machine (JVM) and the Java language have been foundational in the execution of many big data analytics applications and frameworks.
This article describes new technology from Oracle that is packaged as a standalone library and is engineered to streamline Java analytics. This standalone library uses the Java Stream API, an Oracle Solaris library (libdax), and the Data Analytics Accelerator (DAX) coprocessor provided by Oracle's latest SPARC processors, providing extreme performance while using drastically fewer compute resources.
First, this article gives a brief overview of the Java 8 Stream API and the value it brings to writing data analytics code with ease. Then it describes the automatic performance benefits of streams code. Further, it gives a brief overview of the DAX coprocessor and the standalone library that offloads streams functions to DAX.
Java 8 Stream API
The Stream API was introduced in Java 8. One of its key capabilities is to process data in collections such as an SQL query, which simplifies data processing. Using it, you can write very abstract query-like code leveraging the Stream API without going into the details of iterating over the collection entities.
Consider the following Java method, which goes over an array list of daily high temperature data and counts the number of days the temperature crossed 90 degrees Fahrenheit (F):
private static int Hotdays_count_nonStreamWay(ArrayList<Integer> Temperature_list)
{
List<Integer> hotDays = new ArrayList<Integer>();
for (Integer t : Temperature_list)
{
if (t > 90)
{
hotDays.add(t);
}
}
return hotDays.size;
}
In a legacy implementation, illustrated by the method Hotdays_count_nonStreamWay(), the code iterates through every element of this collection. The code manually iterates through the Temperature_list array list and creates a new array list called hotDays to hold the days on which the temperature crossed 90 degrees F. Then the code returns the size of the hotDays array list, which indicates the number of hot days.
Consider the following implementation of the same logic using Java 8 streams:
private static int Hotdays_count_StreamWay(ArrayList<Integer> Temperature_list)
{
return(Temperature_list.parallelStream.filter(t->t>90).count());
}
In the streams implementation, illustrated by the method Hotdays_count_StreamWay(), we create a stream out of the array list Temperature_list, leverage the built-in IntStream filter method with the predicate of the temperature crossing 90, and invoke the count method as the terminal operation of this stream pipeline. This approach accomplishes the same result as the legacy implementation. You can see that we are able to write the same logic with much less effort and fewer lines of code. Leveraging an existing library implementation reduces the number of lines of new code, resulting in fewer bugs in writing this logic.
Looking at this code from a performance perspective, the traditional implementation would typically be compiled into serial code as part of a single thread by the compiler without leveraging the large amount of data parallelism in this logic. Even for an advanced compiler to automatically map such code to a (Single Instruction, Multiple Data) SIMD hardware unit, the compiler would have to go through the fine details of the loop body to identify SIMD patterns, which is very tedious. Often, such code results in serial execution. For a typical analytics application, the data could be many million elements, leading to very long execution times for such an implementation. Parallelizing this code manually using primitives such as OpenMP can result in better performance from thread-level parallelism, but it would require even more lines of code and programmer effort.
With streams, as illustrated in the method Hotdays_count_StreamWay(), you explicitly specify whether an operation is data-parallel by using a higher-level, more-abstract way to specify the operation using the parallelStream() construct. With this hint, the Stream library automatically creates multiple threads to process the data in parallel, which results in better performance on a multithreaded or multicore system. While such an implementation brings many performance benefits, it still suffers from some overhead in terms of thread creation, and it consumes more resources on the processor in terms of the utilization of a number of cores. A hardware accelerator targeted to speed up streams-style code can be more performant than a thread-parallel implementation and get the work done with dramatically fewer resources on the chip.
DAX for Streams Acceleration
The DAX coprocessor on systems that contain Oracle's SPARC M7 or S7 processors (for example, the SPARC T7-1, SPARC M7-16, and SPARC S7-2 systems) comes with Software in Silicon features through which many higher-level data-parallel functions are embedded in the processor. DAX can perform specialized functions—including Scan, Select, Extract, Fill, and Translate—at blindingly fast speeds. While these Software in Silicon functions speed up database queries by multiple times, they are also a perfect fit for speeding up similar functionality in higher-level languages such as the Java 8 Stream API. Figure 1 shows a comparison between a commodity x86 processor and Oracle's SPARC S7 processor.
I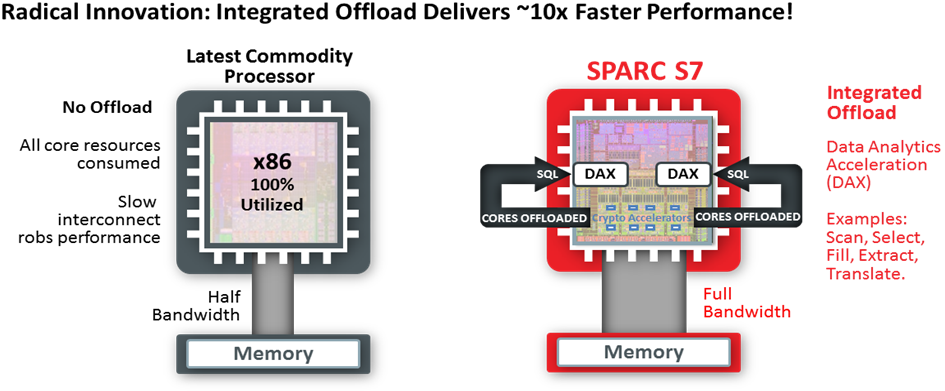
Figure 1. Commodity x86 processor versus SPARC S7 processor
DAX is exposed to Java by the Stream API. Therefore, you can expose DAX to data analytics frameworks that are written in Java and other JVM languages such as Scala that can call Java APIs. For example, you can call Stream APIs from within a program running on Apache Spark and get all the benefits that DAX provides.
Standalone Library
The standalone library provided as a .jar file contains a new package, com.oracle.stream, with the same interface as that of the standard Stream API with offloads to DAX. The library offloads integer stream filter, allMatch, anyMatch, noneMatch, map, count, and toArray functions to DAX when that is profitable. With a minor change to the import statement in the source files, you can use this library with existing code that uses the Stream API. The following table provides a mapping of the stream functions to DAX primitives:
| Stream Operation | DAX Primitive | Description |
| IntStream.filter | Scan and Select | Returns a stream consisting of the elements of this stream that match the given predicate |
| IntStream.allMatch | Scan | Returns whether all elements of this stream match the provided predicate |
| IntStream.anyMatch | Scan | Returns whether any elements of this stream match the provided predicate |
| IntStream.noneMatch | Scan | Returns whether no elements of this stream match the provided predicate |
| IntStream.filter.count | Scan | Returns a count of the elements of this stream that match the given predicate |
| IntStream.filter.toArray | Scan and Select | Returns an array containing the elements of this stream that match the given predicate |
| IntStream.map(ternary).toArray | Scan, Select, and Extract | Returns an integer array containing 0 or 1 after applying the given ternary operator to the elements of this stream |
The flowchart in Figure 2 shows the control flow in the system architecture. The user Java code making use of the Stream API is the target for offload. The implementation has two parts. One part is realized as a Java library shared as a .jar file for use on the Software in Silicon developer (SWiSDev) cloud. The other part is the back-end C library that is shared as a .so file for use on the SWiSDev cloud.
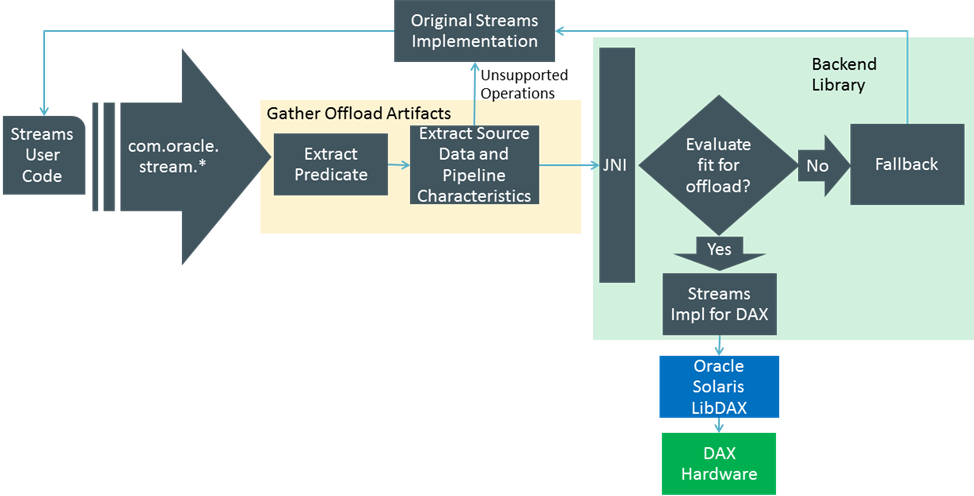
Figure 2. Control flow in the system architecture
First, the offload artifacts are gathered in terms of predicate, pipeline characteristics, and the source data. The offload artifacts are checked against a few quick rules to determine if offloading is possible. If the offload artifacts are not conducive to offloading, the execution falls back to the traditional stream implementation. If the offload artifacts are conducive to offloading, the JNI gateway is invoked with the offload artifacts. Runtime decisions are made regarding whether to run an operation on the DAX coprocessor or on the core based on detailed heuristics that determine profitability in the back-end library. Only the streams marked as parallel—where you explicitly specify that the operation on the collection of objects can run in parallel—are offloaded to DAX,. This means that you specify explicit SIMD processing for each element of the collection independently.
Use Cases
The use cases for leveraging this technology involve SQL-style Java, for example, weather analysis, top-N integers, outlier detection, cube building, percentile calculators, and the K-Nearest Neighbor (KNN) algorithm.
The standalone library for offloading streams functions to DAX achieves up to 22 times faster execution of Java-based analytics applications at significantly lower resource utilization. When analytics operations are offloaded to DAX, the cores can be freed for other operations enabling massive consolidation of Java analytics applications on Oracle Cloud, which results in improved response times, less resource consumption, and cooler data centers. With this library, customers with existing Java applications running on the cores can add analytics capabilities almost at zero cost in terms of resources, making Oracle's SPARC systems the ideal platform for real-time analytics. This also potentially extends Oracle's Software in Silicon benefits from Oracle Database to Java applications including distributed data processing frameworks in Java.
Because the DAX hardware is exposed through an existing Java API, you can write platform-agnostic Java code that gets automatically offloaded to DAX "under the hood" on a SPARC platform.
Historical weather analysis includes the following use cases:
-
Query 1:
Weather_data.parallelStream().filter(w->w.temp>90).count()
This query, which determines the number of times the temperature crossed 90 degrees F, runs approximately 10X faster on DAX.
-
Query 2:
Weather_data.parallelStream(). allMatch(w->w.temp<100)
This query, which tests whether the temperature is always less than 100 degrees F, runs approximately 20X faster on DAX.
The chart in Figure 3 shows the potential of this technology in speeding up some of the workloads that Oracle has experimented with:
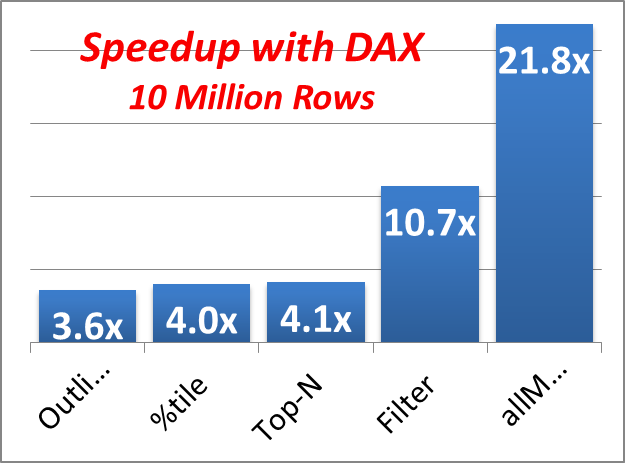
Figure 3. Examples of workloads that can be sped up by using DAX
Best Practices for Using the Standalone Library for Offloading Streams Functions to DAX
- Use only combinations of the supported operations in the pipeline that are intended to be accelerated. Move operations not supported into a separate pipeline (that is not accelerated).
- The source data of the pipeline should be an integer array (or an array list).
- The predicate can include comparison operators with AND and OR operations. Avoid arithmetic operations inside predicates to ensure offload.
- Use constants and static variables in lambda expressions. Instance variables and local variables can be assigned to a final static variable before usage in a lambda expression.
- Choose a data size higher than 50,000 elements for profitable offloads.
Availability of the Standalone Library for Offloading Streams Functions to DAX
The standalone library for offloading streams functions to DAX is available for use on the SWiSDev cloud, which enables you to try out DAX. You can use the binaries compiled with the standalone library for offloading streams functions to DAX to experiment with your own use cases.
To use the standalone library, include the following import statements in the source code that is intended to be accelerated:
import com.oracle.*;
import com.oracle.stream.*;
To avoid conflicts, you may want to remove other import statements to java.util.stream and java.util.Arrays in the source files.
To compile, please add the following to the javac command line:
-cp /usr/lib/sparcv9/comOracleStream.jar
To run, please add the following to the javac command line:
-Xbootclasspath/p:/usr/lib/sparcv9/comOracleStream.jar
See Also
About the Author
Karthik Ganesan is a senior engineer and project lead at Oracle. He is currently working in the Cloud Platforms, Applications, and Developers organization, focusing on the Software in Silicon technologies for Oracle's SPARC platforms. He received his PhD in computer engineering and a Master of Science in Engineering from the University of Texas at Austin. He received his Bachelor of Engineering from Anna University, India. Karthik has given more than 20 talks at many international conferences, authored 15+ publications with 150+ citations and holds multiple US patents. Karthik's areas of interests include cloud platform architecture, Software in Silicon technologies, Java, and big data analytics.
Follow us:
Blog | Facebook | Twitter | YouTube