Hello Community,
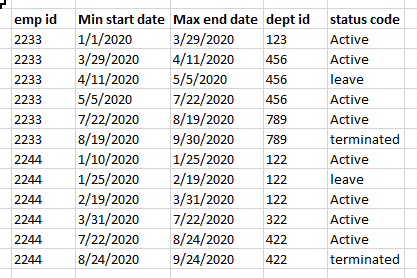
I have a simple data set like below:
 I need minimum start date & max end date of an employee whenever there is a dept id change or status code change.
I need minimum start date & max end date of an employee whenever there is a dept id change or status code change.
So i wrote this formula for Min start date- select emp id, dept id, status code , min(start date) from tablename group by emp id, dept id, status code.
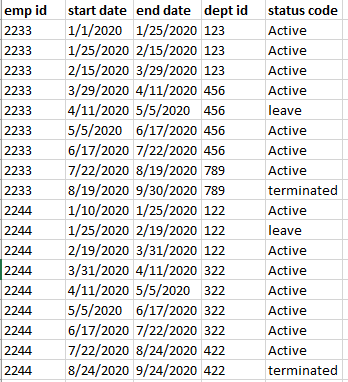
I've got the below result :
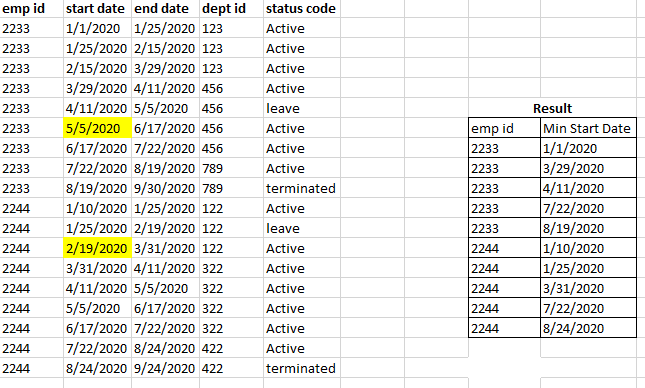 The highlighted dates are missing in my result because dept id and status code got repeated. Since i am taking min start date, its not considering those records.
The highlighted dates are missing in my result because dept id and status code got repeated. Since i am taking min start date, its not considering those records.
Likewise, i need to get max end date also.
I hope i explained the problem.
Any help would be greatly appreciated.
Thanks.
Update - Adding sample data and expected ouptut.
create table employee(
emp_id int, start_date date, end_date date, dept_id int, status_code varchar(100));
insert into employee values
('2233','1/1/2020','1/25/2020','123','Active'),
('2233','1/25/2020','2/15/2020','123','Active'),
('2233','2/15/2020','3/29/2020','123','Active'),
('2233','3/29/2020','4/11/2020','456','Active'),
('2233','4/11/2020','5/5/2020','456','Leave'),
('2233','5/5/2020','6/17/2020','456','Active'),
('2233','6/17/2020','7/22/2020','456','Active'),
('2233','7/22/2020','8/19/2020','789','Active'),
('2233','8/19/2020','9/30/2020','789','Terminated'),
('2244','1/10/2020','1/25/2020','122','Active'),
('2244','1/25/2020','2/19/2020','122','Leave'),
('2244','2/19/2020','3/31/2020','122','Active'),
('2244','3/31/2020','4/11/2020','322','Active'),
('2244','4/11/2020','5/5/2020','322','Active'),
('2244','5/5/2020','6/17/2020','322','Active'),
('2244','6/17/2020','7/22/2020','322','Active'),
('2244','7/22/2020','8/24/2020','422','Active'),
('2244','8/24/2020','9/24/2020','422','Terminated')
Expected Output: