Hi,
We have a process which can generate the following data rows each run (Per Day):
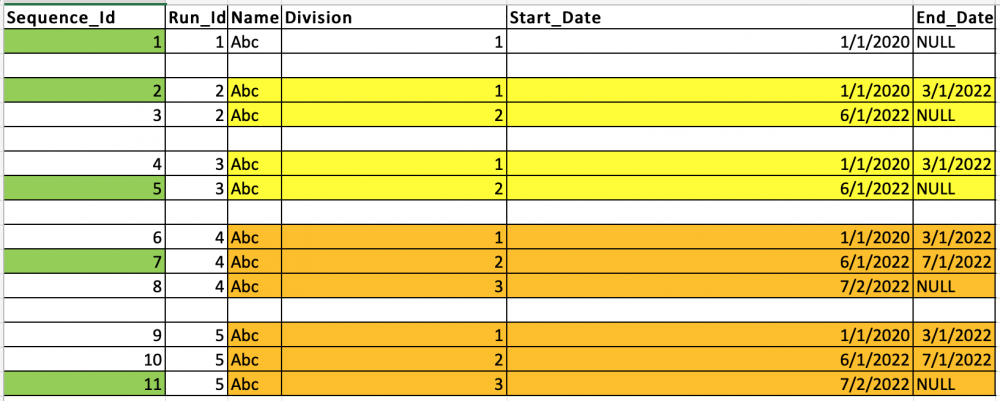 As part of the query I need to make sure that anytime a 2nd row appears for the same subject - We first select the terminated row (In this case the 3/1/2022 in Run 2) and then for each subsequent runs, just select the 2nd row with a start date of 6/1/2022 for Run 3, Run 4...
As part of the query I need to make sure that anytime a 2nd row appears for the same subject - We first select the terminated row (In this case the 3/1/2022 in Run 2) and then for each subsequent runs, just select the 2nd row with a start date of 6/1/2022 for Run 3, Run 4...
The challenge I am facing is how to make sure I pick the first row in Run 2 but in all subsequent runs - just pick the 2nd row for the same subject.
Any ideas or help would be greatly appreciated. Sharing a livesql link, please check:
Oracle Live SQL - Script: Need help with writing a query! (0 Bytes)*Note - The 2nd row that appears can also have an end date
=====================================================================
Edit1:
I have updated the screenshot above + livesql link in the hopes of making the question clearer. Please note the highlighted rows member data is exactly same. And the row highlighted in green denotes the correct row we need per run_id and name combination.
Some background on the process: The target table will be initially empty but once we go live and the process starts running, it will contain member (Eg Abc from above) records with their division start and end dates (Also shown in the above screenshot).
Lets say we have a function that gets us the sequence_id based on run_id and name inputs:
fn_get_sequence_id(run_id, name) should get us the following results based on the data above
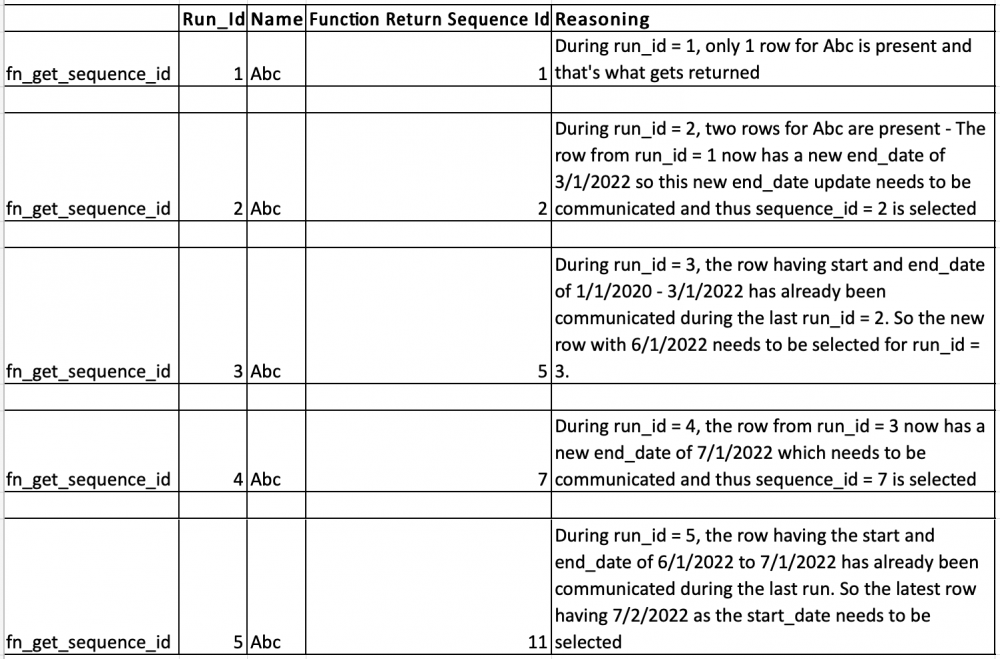 Please advise if additional information/clarification is needed.
Please advise if additional information/clarification is needed.
=====================================================================
Thanks!