by Rick Ramsey with contributions from Jean-Pierre Dijcks and Martin Gubar
How to use SQL and Oracle Big Data SQL to get the most out of your big data.
Big data technologies such as Hadoop, NoSQL, and relational databases offer powerful ways to manipulate different types of data. Each provides excellent tools for gathering, storing, and analyzing particular aspects of big data. For instance, the Hadoop Distributed File System (HDFS) can cost effectively handle large volumes of structured and unstructured data. Generic NoSQL databases (key-value stores) provide a flexible data model, horizontal scalability, low latency, and simple APIs/interfaces. And relational databases such as Oracle Database are powerful, ubiquitous, and already store a great deal of both transactional and enterprise warehouse data.
However, you can extract greater business value from your big data when you access all three holistically. For instance, instead of simply identifying customers who spend the most on your website so you can target them with a marketing campaign, you can identify customers who spend the most on your website but have recently stopped visiting. You could then develop a more targeted promotion to encourage them to return.
The tool that enables you to do that is Oracle Big Data SQL. This article helps you understand your data requirements, the major big data technologies available to you, and how to get the most out of them by writing unified queries with Oracle Big Data SQL.
Contents of this article:
Understanding Your Data
Before understanding how to use Oracle Big Data SQL to query data in different data stores, it's a good idea to understand the nature of your data.
At-Rest Versus Streaming Data
There is some debate about the different states of data and the exact boundaries between those states (see this Wikipedia entry). For our discussion, we will simply define data at rest as data that has already been stored in persistent storage such as tape or disk. Although you may load it into an application to analyze it at some point in the future, it "already happened," so to speak.
Streaming data, on the other hand, is data that is being generated in real time from financial transactions, from sensors, from the location of items in the Internet of Things (IoT), from point-of-sale (POS) transactions, and so on. It might end up being converted into data at rest, but for the moment, it is "live."
Why is this distinction between data at rest and streaming data important? Because you will process them differently. For instance, the newness of streaming data makes it both highly valuable and highly perishable. For instance, if you want to make an offer to the mobile phone of a customer who is walking past a particular Starbucks location, the customer's location is perishable data. In a few minutes, the customer will be too far away from that location to make the offer attractive. As a result, you'll want to make speed a processing priority for streaming data over, say, cost. Later, when that data has been converted to data at rest, you can switch the processing focus to batch or ad hoc analytic processing (for example) or use it in a discovery lab to produce the model used to generate the customer offer!
The recommendations in the remainder of this article will focus on data at rest, because that's the type of data on which most big data implementations are focusing.
Processing Requirements
The processing requirements for big data are primarily determined by three factors:
- Performance
- Security
- Cost
These are the major characteristics worth considering for each category:
Performance
- Single-record read/write performance: How well the technology can deal with requests for individual records
- Bulk write performance: How well a system can deal with bulk inserts/ingests
- Complex query response times: How well the system handles a request for complex analytics queries
- Concurrency: The ability of the technology to drive large concurrent access to the system
Security
- General user security: How well data can be secured for the general user population
- Privileged user security: How well data can be secured from administrators and other privileged users
- Governance tools: How mature the platforms' tooling is to ensure proper governance of data elements and, for example, comply with regulations around data
Cost
- System per TB cost: The cost of a terabyte of data when stored in this technology
- Backup per TB cost: The cost of a terabyte of data when backed up or in a disaster recovery (DR) system
- Skills acquisition cost: The cost of the new skills, if required, and their relative scarcity
- Integration costs: The costs associated with integrating the data with existing applications and system infrastructure
Figure 1 plots these criteria onto a graph. The numbers are approximations, but in general, a higher number is better. For example, the score of 5 for concurrency in the case of NoSQL indicates that it supports concurrency exceptionally well. For cost, higher numbers indicate a higher cost, but not the actual cost per TB.
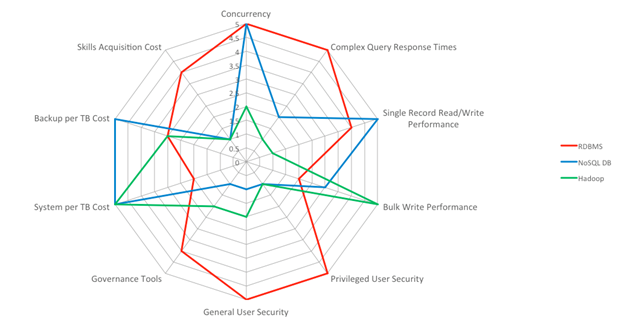
Figure 1. A graph of performance, security, and cost criteria.
What are you supposed to do with the information in the graph above? Use it to identify the appropriate data store based on your application requirements. Do you care more about system per TB cost or complex query response times for large number of concurrent users? The following section summarizes the strengths and weaknesses of the three major big data technologies. By comparing the requirements of your application in each of these areas to the strengths of the major technologies, you'll have a better idea of which technology to use for what.
Understanding Big Data Technologies
Each of the top three technologies most commonly used for big data—HDFS, generic NoSQL databases (key-value stores), and Oracle Database (a relational database)—has particular strengths. One way of evaluating those strengths is to evaluate each technology's ability to handle the following factors:
- Ingestion: The loading of data into the technology
- Disaster recovery: The ability to recover from failures
- Access: The ability to access data and perform a simple query or more complex analysis
Ingestion
HDFS ingests data with a simple "put" API call. Each file is broken into 256 MB blocks as it performs a synchronous write. Data is written as presented and stored as presented.
NoSQL stores each entry by its key, and the entry can be of any length or content. It has very high write rates and instant retrieval when accessing the data through a key or index, which is ideal for certain high-performance requirements. To achieve those high retrieval rates, data is stored asynchronously, which can produce inconsistent reads. This trade-off might be acceptable for applications where eventual consistency can be tolerated. It would not, however, be acceptable for a POS application that needs to have consistent data.
A financial point of sale application, in which a single transaction involves multiple operations, would do better with a relational database, which has ACID (atomicity, consistency, isolation, durability) compliance and supports a rich transaction model. A relational database ingests data using SQL, so by the time the data is stored, it has been fully parsed and validated. If, for instance, the relational database detects inconsistent data in any of the operations, it rejects the entire transaction. It accepts the transaction only when all the data has been validated.
Disaster Recovery
All three data stores replicate their data for high availability (HA). However, each uses a different method, so which is better for your application depends on the recovery needs of your application.
HDFS automatically replicates its data blocks within a cluster—typically creating three copies. This offers strong support for failure tolerance within that cluster. However, replicating data outside the cluster to another data center is often critical for meeting HA requirements. HDFS generally achieves this requirement through batch processing (distcp), periodically copying large files across the network. This process works well, but it is coarse-grained and less sophisticated than products such as Oracle GoldenGate. It provides an automated way of copying files across data centers—where the unit of work is at the block level (or 256 MB chunk of data).
Oracle Database provides much more fine-grained and robust HA support through the Oracle Maximum Availability Architecture (this document offers a quick summary). Unlike HDFS, which offers batch backup of large files, Oracle Database replicates records with zero data loss...and zero outages.
Oracle Database replicates data by record using established tools such as Oracle GoldenGate. With Oracle Database, the system automatically retrieves lost or damaged records. Oracle Database Maximum Availability Architecture replicates transactional data across data centers using established tools such as Oracle GoldenGate and Oracle Active Data Guard. This solution places a premium on maximum availability and performance, so if a particular server is overloaded, it moves the processing to a different server. Furthermore, Oracle Database provides failover across data centers.
NoSQL databases feature built-in replication from the master node to replicas—with built-in support for cross data center replication. Oracle NoSQL Database has an intelligent driver that monitors workloads and server availability, so it can provide automatic load balancing. While this can lead to eventual consistency, it also greatly simplifies disaster recovery and geographic scale.
Oracle NoSQL Database actually has a settable durability. At one extreme, applications can request that write requests block until the record has been written to stable storage on all copies. At the other extreme, applications can request that write operations return as soon as the system has recorded the existence of the write, even if the data is not persistent anywhere.
So, those are the options—your application requirements will drive your choice.
Access
To retrieve a single "record" from HDFS, the system reads the whole file (typically a number of blocks) and then presents the desired results to the client application. In Oracle Database terminology, every HDFS read is going to be a "full table scan," whether one record or the entire contents of the file originally stored is of interest.
When using SQL to access the data, Hive optimizes for retrieval by enabling files to be split into multiple files. Hive optimizes for retrieval by partitioning data files based on an attribute, such as time, country, and so on. For example, all files containing data for January will go into the Jan folder, all files containing data for February will go into the Feb folder, and so on. This splitting reduces I/O operations because the files can be ignored; that is, partitions can be pruned when a query is filtering out that information.
A NoSQL database combines some optimization for access (the keys to each of the records) with some optimizations for ingest and flexibility (the unparsed value elements of the records). The combination of these elements enables fast serving of individual records to an application through what in Oracle Database speak would be an "index lookup."
Because Oracle Database parses the data when ingesting it, optimizing the file formats in which the data is stored under the covers can optimize retrieval speeds. On top of that, expansive schema modeling constructs enable various access paths to be created and optimized for index structures, partitioning schemes, in-memory columnar formats, and so on.
Summary of the Three Technologies
Figure 2 summarizes the method each technology uses for ingestion, DR, and access.
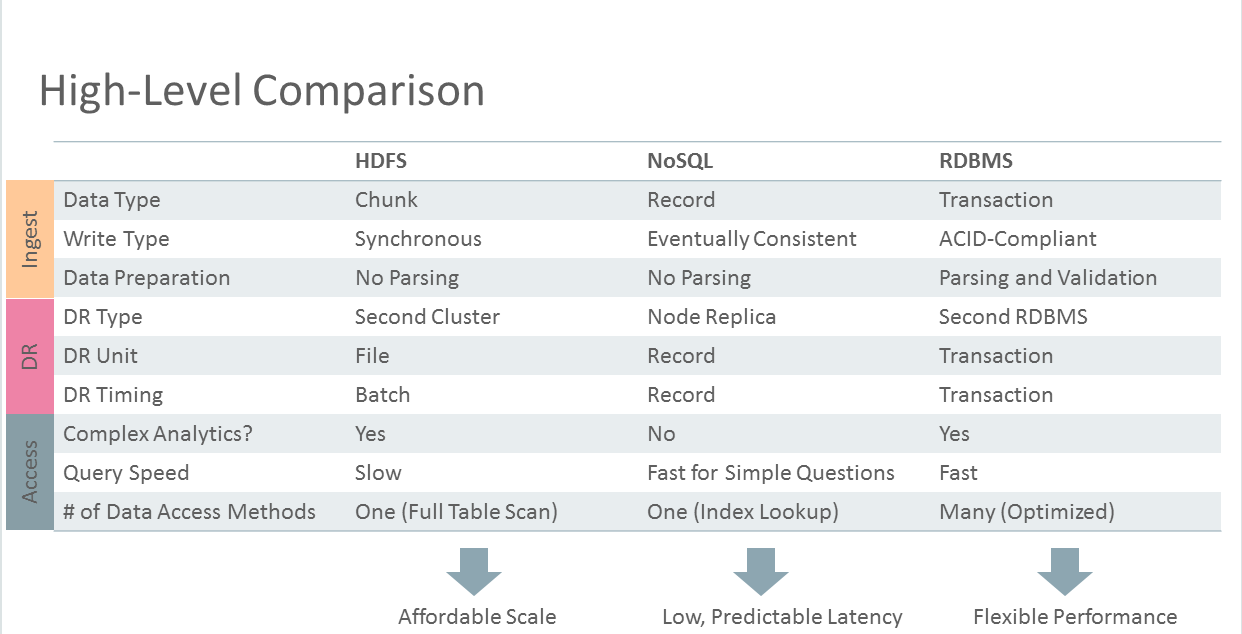
Figure 2. Comparison of the three technologies.
Looking at the table, you can begin to classify the core use for each technology as follows:
- HDFS: Affordable scale
- NoSQL databases: Predictable, low-latency workloads
- Oracle Database: Transaction support, tunable performance, and rich SQL analytics
Unifying Queries Across Big Data Stores Using Oracle Big Data SQL
Based on the performance, cost, security, and other requirements of your applications, the optimum solution can be a big data solution that relies on multiple technologies. Unfortunately, because those technologies use different APIs, you can wind up with data silos:

Figure 3. Data silos created by different technologies.
Because the entire point of using big data is to make better decisions from a greater amount and variety of data, it really helps if you can find a way to bridge the different APIs. Oracle Big Data SQL does exactly that.

Figure 4. Oracle Big Data SQL can bridge data silos.
About SQL
SQL is sometimes referred to as the lingua franca of data. It has been around for 40 years. Most IT shops already have extensive investments in SQL implementations and skill sets. As blogger Klaker-Oracle points out in the blog "Why SQL Is Becoming the Go-To Language for Big Data Analysis," using SQL also allows you to access the "legions of developers" who already know SQL. There is, in fact, a well-established SQL ecosystem:
| "And now there is an explosion of SQL-based implementations designed to support big data. Leveraging the Hadoop ecosystem, there is: Hive, Stinger, Impala, Shark, Presto and many more. Other NoSQL vendors such as Cassandra are also adopting flavors of SQL. Any platform that provides SQL will be able to leverage the existing SQL ecosystem." |
About Oracle Big Data SQL
Oracle Big Data SQL simplifies access to all your data. In addition to simplifying access to your Hadoop, NoSQL, and Oracle Database data, it helps you discover and act upon your insights faster. Oracle Big Data SQL inherits the enterprise-grade security umbrella of authentication, authorization, auditing, redaction, and so on, from Oracle Database, which keeps your big data as governed and secure as all your data.
Two key innovations that enable Oracle Big Data SQL are big data–enabled Oracle Database external tables and Smart Scan—the same technology that is key to Oracle Exadata performance. Oracle Database external tables now understand Hadoop features such as Hive and HDFS. They combine this understanding with Smart Scan to efficiently process data on a Hadoop cluster. Applications can now query Hadoop and NoSQL through the external table—just as they would any other table in Oracle Database—enabling unified queries across the big data platform. A unified query is simply a query that accesses data regardless of where it is stored, whether in a traditional relational database, in NoSQL, or in large file systems such as HDFS.
Older approaches to unified queries, such as data shipping and language-level federation, have significant drawbacks. Oracle Big Data SQL uses the query franchising approach, which was designed with the following priorities in mind:
- It must integrate seamlessly into your existing infrastructure in a way that provides direct benefits to your business.
- You should be able to apply your existing SQL queries to your newly acquired big data without modification, and they should still work. In fact, they should result in better data analysis because of the greater variety of data that you can analyze.
- When you want to take advantage of the greater amount of data, you will be able to expand those queries with new attributes that provide finer analytical granularity.
Priority 3 is of particular importance because the nature and quantity of big data should help you make better, more granular business decisions.
Following is an example of how you could extend an existing query to provide finer analytical granularity.
An Example
Let's assume that you want to identify the customers that
- Spend the most (monetary query)
- Visit your site the most often but haven't visited in a while (recency and frequency queries)
The monetary information (rfm_monetary) is stored in the database. The recency and frequency information is stored in Hadoop's click-data logs. Your intent is to extract information from both data stores so you identify the customers you want to target. Here's how you could do that with a single query using Oracle Big Data SQL. Below, the query has been broken up into its logical parts:
-- Customer Recency, Frequency and Monetary query
-- Find important customers who haven't visited in a while
WITH customer_sales AS
-- Sales and customer attributes
SELECT m.cust_id,
c.last_name,
c.first_name,
c.country,
c.gender,
c.age,
c.income_level,
NTILE (5) over (order by sum(sales)) AS rfm_monetary
FROM movie_sales m, customer c
WHERE c.cust_id = m.cust_id
GROUP BY m.cust_id,
c.last_name,
c.first_name,
c.country,
c.gender,
c.age,
c.income_level
The first part of the script above uses the NTILE (5) function to sort customers by sales and divide them into quintiles according to the amount of money they have spent on your site. It extracts the customer ID and other useful information about each customer.
Each customer is assigned an rfm_monetary score from 5 (highest) to 1 (lowest).
The second part of the script, below, is very similar to what was done to data stored in Oracle Database. However this time, the analytics are applied to the click-data in HDFS. Customers are organized into quintiles using the NTILE function based on when they last came to the site and their activity on the site. So, we now have behavioral information regarding the recency of visits and usage frequency.
click_data AS (
-- clicks from application log
SELECT custid,
NTILE (5) over (order by max(time)) AS rfm_recency,
NTILE (5) over (order by count(1))
FROM movielog_v
GROUP BY custid )
Then it combines those lists into combined rfm scores to order customers according to how much they spend, how often they come to the site, and how active they are. What you're looking for are the customers with the highest spend (rfm_monetary >= 4) that have not visited recently (rfm_recency <= 2). That would help you target them with perhaps a different marketing campaign.
SELECT c.cust_id,
c.last_name,
c.first_name,
cd.rfm_recency,
cd.rfm_frequency,
c.rfm_monetary,
cd.rfm_recency*100 + cd.rfm_frequency*10 + c.rfm_monetary AS
rfm_combined,
c.country,
c.gender,
c.age,
c.income_level
FROM customer_sales c, click_data cd
WHERE c.cust_id = cd.custid
AND c.rfm_monetary >= 4
AND cd.rfm_recency <= 2
ORDER BY c.rfm_monetary desc, cd.rfm_recency desc
Some of the data being queried is coming from Hadoop, some from the database. The beauty of using Oracle Big Data SQL is the person writing the query doesn't need to know which data is stored where.
How does Oracle Big Data SQL do this? By using the external tables in Oracle Database. The table knows where things are stored. All you need to know as the script writer is what data you want and how you want to manipulate it.
Conclusion
Each of the major big data technologies provides a particular type of business value. However, you can increase the total value your big data implementation provides to your business by using the unified queries of Oracle Big Data SQL to analyze the data across all those technologies. SQL is a powerful language with an established knowledge base, and Oracle Big Data SQL provides the tools to get the most out of your big data.
See Also
About the Authors
Rick Ramsey started his high-tech training as an avionics technician in the US Air Force. While studying economics at UC Berkeley, he wrote reference manuals and developer guides for two artificial intelligence languages, ART and SYNTEL. At Sun Microsystems Ramsey wrote about hardware, software, and toolkits for developers and sysadmins, and he published All About Administering NIS+. Ramsey served as information architect before joining Sun's BigAdmin website, which morphed into the Systems Community at Oracle. He left Oracle in May 2015.
Jean-Pierre Dijcks has a master's degree in industrial engineering from the University of Twente in the Netherlands. Data has been the leading tenet in his 15+ years in information technology. After a start in data integration and data warehouse consulting, Dijcks took on product management roles at Oracle for Oracle Warehouse Builder and Oracle Database parallel execution. Currently he is Master Product Manager for Oracle Big Data Cloud Service and Oracle Big Data Appliance and plays a leading role in Oracle's big data platform strategy.
Martin Gubar is part of the product management team at Oracle, focusing on Oracle's big data platform and related products. He has been responsible for delivering enabling tools to help people become successful with Oracle's big data technology. Gubar has a long history at Oracle; he was the lead product manager for business intelligence, a member of the online analytical processing (OLAP) product management group, and a director of marketing for OLAP technology.