Hi, I have a requirement to find an ID from a lookup table based on the closest value. I have a main table and a lookup table. Based on the value from the main table, the query should return an ID of the closest value from the lookup table.
create table measure_tbl(ID number, measure_val number (3,2));
insert into measure_tbl values(1,0.24);
insert into measure_tbl values(2,0.5);
insert into measure_tbl values(3,0.14);
insert into measure_tbl values(4,0.68);
commit;
create table Nom_val_lkp(LKP_ID number, nom_val number(3,2));
insert into Nom_val_lkp values(1,0.1);
insert into Nom_val_lkp values(2,0.2);
insert into Nom_val_lkp values(3,0.3);
insert into Nom_val_lkp values(4,0.4);
insert into Nom_val_lkp values(5,0.5);
insert into Nom_val_lkp values(6,0.6);
insert into Nom_val_lkp values(7,0.7);
insert into Nom_val_lkp values(8,0.8);
insert into Nom_val_lkp values(9,0.9);
commit;
The result should look like:
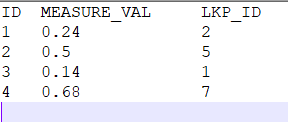 How can I form a query to find a closest match of the measure value from the lookup table and pick the relevant ID in a query. Please help.
How can I form a query to find a closest match of the measure value from the lookup table and pick the relevant ID in a query. Please help.