in Oracle Solaris 11.1
by [Alexandre Borges ](/people/Alexandre Borges)
](/people/Alexandre Borges)
Part 9 of a series that describes the key features of ZFS in Oracle Solaris 11.1 and provides step-by-step procedures explaining how to use them. This article focuses on how to increase the size of a mirrored pool and how to deal with a faulted disk.
Doubtless, there are a lot of ZFS dataset and pool properties and there should be an entire book to explain them and give some examples. Among the ZFS pool properties, it's worth talking about one in particular: autoexpand.
The autoexpand property can be used in cases where the system runs an application that needs a lot space, and the pool doesn't have the required amount of space available on disk yet. Another scenario that happens in some environments is when the mirror pool is very small for the application, and the mirror pool's size must be increased. In both cases, we can use the autoexpand property to cause an automatic expansion of the underlying devices.
Note: As explained in Part 1 of this series of articles, we are using a host named solaris11-1 as our server, and we installed the server in a virtual machine using Oracle VM VirtualBox. We will be using Oracle VM VirtualBox to perform some of the steps in this article.
Increasing the Size of a Mirrored Pool
The following demonstration is very simple and will use two 4-GB disks.
First, we create a mirrored pool named mir_pool and a file system in this pool named fs_1. Then, we copy some files into this file system and list the details of the created pool and file system.
root@solaris11-1:~# zpool create mir_pool mirror c8t9d0 c8t10d0
root@solaris11-1:~# zfs create mir_pool/fs_1
root@solaris11-1:~# cp -r /root/Desktop/Hacking/* /mir_pool/fs_1/
root@solaris11-1:~# zfs list -r mir_pool
NAME USED AVAIL REFER MOUNTPOINT
mir_pool 1.28G 2.63G 32K /mir_pool
mir_pool/fs_1 1.28G 2.63G 1.28G /mir_pool/fs_1
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t9d0 ONLINE 0 0 0
c8t10d0 ONLINE 0 0 0
errors: No known data errors
The amazing steps start now: We are going to replace both 4-GB disks with two 16-GB disks, because the application needs a bigger pool and file system. To accomplish this, a careful step-by-step procedure must be done, because there is real data in the pool. Therefore, we need to replace one disk (c8t9d0), wait for its resilvering to be completed, and then do the same process with the other disk (c8t10d0).
First, detach the first disk (c8t10d0) from storage pool mir_pool by running the following command:
root@solaris11-1:~# zpool detach mir_pool c8t10d0
After detaching the disk, check the pool status by running the following command:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
c8t9d0 ONLINE 0 0 0
errors: No known data errors
According to the output, storage pool mir_pool is healthy, so verify that the file system mirror_pool/fs_1 is still mounted by executing the zfs list command, and then attach a new disk by executing the zpool attach command, as shown below:
root@solaris11-1:~# zfs list -r mir_pool
NAME USED AVAIL REFER MOUNTPOINT
mir_pool 1.28G 2.63G 32K /mir_pool
mir_pool/fs_1 1.28G 2.63G 1.28G /mir_pool/fs_1
root@solaris11-1:~# zpool attach mir_pool c8t9d0 c8t5d0
To follow the pool resilvering process, execute the following command:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function in a degraded state.
action: Wait for the resilver to complete.
Run 'zpool status -v' to see device specific details.
scan: resilver in progress since Thu Jul 03 19:19:00 2014
85.8M scanned out of 1.28G at 2.68M/s, 0h7m to go
**81.6M resilvered, 6.54% done**
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t9d0 ONLINE 0 0 0
c8t5d0 DEGRADED 0 0 0 (**resilvering**)
errors: No known data errors
Wait a few minutes and run the following commands:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.28G in 0h4m with 0 errors on Thu Jul 03 19:23:32 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t9d0 ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
errors: No known data errors
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 3.97G 1.28G 2.69G 32% 1.00x ONLINE -
The pool was resilvered successfully.
It's time to repeat the same steps for the second disk. We're going to replace it with a bigger disk. First, run the following command:
root@solaris11-1:~# zpool detach mir_pool c8t9d0
Confirm that the mir_pool storage pool has only one disk by running the following command:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.28G in 0h4m with 0 errors on Thu Jul 03 19:23:32 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
errors: No known data errors
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 3.97G 1.28G 2.69G 32% 1.00x ONLINE -
Attach the new second disk (c8t6d0) to the mir_pool storage pool by executing the following command:
root@solaris11-1:~# zpool attach mir_pool c8t5d0 c8t6d0
After a few minutes, you can see that mir_pool continues resilvering. It'll be on degraded status until the resilvering has finished:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function in a degraded state.
action: Wait for the resilver to complete.
Run 'zpool status -v' to see device specific details.
scan: resilver in progress since Thu Jul 03 19:32:17 2014
171M scanned out of 1.28G at 4.63M/s, 0h4m to go
168M resilvered, 13.06% done
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t5d0 ONLINE 0 0 0
c8t6d0 DEGRADED 0 0 0 (resilvering)
errors: No known data errors
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 3.97G 1.28G 2.69G 32% 1.00x DEGRADED -
Sometime later, the mirror will be re-established and its status is OK again:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.28G in 0h3m with 0 errors on Thu Jul 03 19:35:33 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
c8t6d0 ONLINE 0 0 0
errors: No known data errors
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 3.97G 1.28G 2.69G 32% 1.00x ONLINE -
Wow...we have a serious problem: Both 4-GB disks were replaced with the 16-GB disks, but the pool size persisted. At this point, we require the help of the autoexpand property to increase the size of the pool:
root@solaris11-1:~# zpool set autoexpand=on mir_pool
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 16.0G 1.28G 14.7G 8% 1.00x ONLINE -
root@solaris11-1:~# zfs list -r mir_pool
NAME USED AVAIL REFER MOUNTPOINT
mir_pool 1.28G 14.4G 32K /mir_pool
mir_pool/fs_1 1.28G 14.4G 1.28G /mir_pool/fs_1
Fantastic! Now the mir_pool pool has grown to 16 GB.
Dealing with Faulted Disks
Sometimes disks fail, so we need to know how to replace them. The following procedure simulates a problem with a disk and explains the options for handling the problem.
First, let's list the status of the pool:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.28G in 0h3m with 0 errors on Thu Jul 03 19:35:33 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
**c8t5d0** ONLINE 0 0 0
**c8t6d0** ONLINE 0 0 0
errors: No known data errors
To simulate a disk failure, take the c8t5d0 disk offline:
root@solaris11-1:~# zpool offline mir_pool c8t5d0
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scan: resilvered 1.28G in 0h3m with 0 errors on Thu Jul 03 19:35:33 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t5d0 **OFFLINE** 0 0 0
c8t6d0 ONLINE 0 0 0
errors: No known data errors
For the next step, we will power-off the system, and then we will use Oracle VM VirtualBox to remove the old disk that was offlined (NewVirtualDisk20.vdi) from SCSI slot 5 and insert a new disk (NewVirtualDisk22.vdi) in the same slot (see Figure 1 and Figure 2).

Figure 1. Screen showing the old disk in slot 5
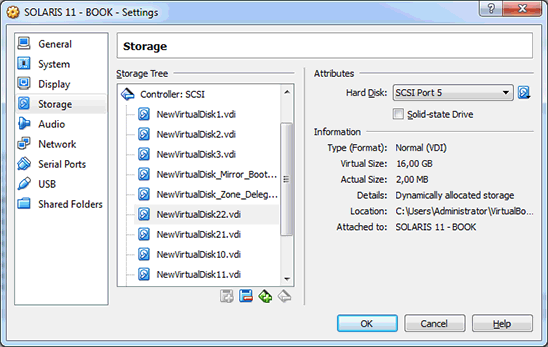
Figure 2. Screen showing the new disk in slot 5
After the disk replacement is done, turn the system on again. Up to this point, the procedure we have performed is typical of what would be done in a real situation.
List the status of the pool again:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using 'zpool online' or replace the device with
'zpool replace'.
scan: resilvered 1.28G in 0h3m with 0 errors on Thu Jul 03 19:35:33 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t5d0 **OFFLINE** 0 0 0
c8t6d0 ONLINE 0 0 0
errors: No known data errors
Disk c8t5d0 continues to be offline. From this point on, there are some good alternatives for managing the situation. If mir_pool has some spare disks, a spare disk would have taken the place of the bad disk automatically. However, there wasn't a spare disk. Adding a spare disk at this point is useless, because the problem happened before adding a spare disk. So, we have to tell Oracle Solaris 11 to logically replace the disk that has been replaced physically:
root@solaris11-1:~# zpool replace mir_pool c8t5d0
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function in a degraded state.
action: Wait for the resilver to complete.
Run 'zpool status -v' to see device specific details.
scan: resilver in progress since Fri Jul 04 01:08:27 2014
137M scanned out of 1.33G at 3.52M/s, 0h5m to go
133M resilvered, 10.07% done
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
replacing-0 DEGRADED 0 0 0
c8t5d0/old OFFLINE 0 0 0
c8t5d0 DEGRADED 0 0 0 (resilvering)
c8t6d0 ONLINE 0 0 0
errors: No known data errors
root@solaris11-1:~#
The replaced disk is resilvering with the existing disk (c8t6d0). After a few minutes, the status is as follows:
root@solaris11-1:~# zpool list mir_pool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mir_pool 16.0G 1.33G 14.6G 8% 1.00x ONLINE -
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.33G in 0h4m with 0 errors on Fri Jul 04 01:13:00 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t5d0 **ONLINE** 0 0 0
c8t6d0 ONLINE 0 0 0
errors: No known data errors
Excellent. The resilvering of the new disk was completed.
To prevent the same problem from happening again, a spare disk will be added. Then, when something goes wrong (for example, a disk fails), the spare can take the place of the failed disk. Creating a spare disk is done by running the following command:
root@solaris11-1:~# zpool add mir_pool spare c8t14d0
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 1.33G in 0h4m with 0 errors on Fri Jul 04 01:13:00 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
c8t6d0 ONLINE 0 0 0
spares
c8t14d0 AVAIL
errors: No known data errors
root@solaris11-1:~#
The spare disk appears and AVAIL indicates it has an available status. Let's pretend a disk is failing by simulating a failure again.
First, put disk c8t6d0 in an offline state:
root@solaris11-1:~# zpool online mir_pool c8t6d0
Then, turn the machine off:
root@solaris11-1:~# shutdown -y -g0
Now we will remove disk c8t6d0 from the virtual machine configuration using the same method we used earlier when learning about the autoexpand property. Notice that Figure 3 shows there isn't any disk in slot 6:
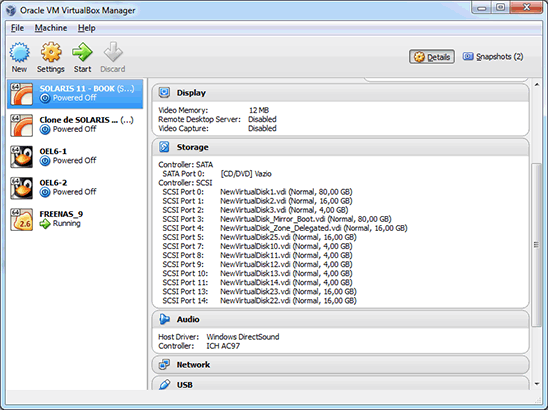
Figure 3. Screen showing there is no disk in slot 6
Now, turn the virtual machine on again.
After performing these past four steps, if we try to bring disk c8t6d0 online again an error will be shown, because there isn't such a virtual disk anymore:
root@solaris11-1:~# zpool online mir_pool c8t6d0
: cannot relabel 'c8t6d0s0': unable to open device
warning: device 'c8t6d0' onlined, but remains in faulted state
use 'zpool clear' to restore a faulted device
And, finally, the spare disk takes its place and resilvering starts:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function in a degraded state.
action: Wait for the resilver to complete.
Run 'zpool status -v' to see device specific details.
scan: resilver in progress since Fri Jul 04 01:58:15 2014
135M scanned out of 1.33G at 6.42M/s, 0h3m to go
131M resilvered, 9.88% done
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t5d0 ONLINE 0 0 0
spare-1 DEGRADED 0 0 0
c8t6d0 **UNAVAIL** 0 0 0
c8t14d0 DEGRADED 0 0 0 (**resilvering**)
spares
c8t14d0 INUSE
errors: No known data errors
Sometime later we can check the status again to verify that resilvering was completed:
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: DEGRADED
status: One or more devices are unavailable in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or 'fmadm repaired', or replace the device
with 'zpool replace'.
Run 'zpool status -v' to see device specific details.
scan: resilvered 1.33G in 0h3m with 0 errors on Fri Jul 04 02:01:23 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
c8t5d0 ONLINE 0 0 0
spare-1 DEGRADED 0 0 0
c8t6d0 UNAVAIL 0 0 0
c8t14d0 ONLINE 0 0 0
spares
c8t14d0 **INUSE**
errors: No known data errors
If we repeat the same steps (turn the virtual machine off, add a disk at SCSI slot position 6 as shown in Figure 4, turn the virtual machine on, and detach the spare disk), at the end, the c8t6d0 disk will be a data disk again after the resilvering process and the c8t14d0 disk will revert to being a spare disk:
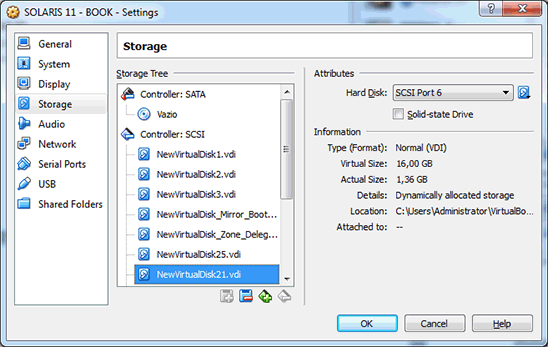
Figure 4. Screen showing a disk in slot 6
root@solaris11-1:~# zpool status -x
all pools are healthy
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 64.5K in 0h0m with 0 errors on Fri Jul 04 00:41:28 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
spare-1 ONLINE 0 0 0
c8t6d0 ONLINE 0 0 0
c8t14d0 ONLINE 0 0 0
spares
c8t14d0 **INUSE**
errors: No known data errors
To force the c8t14d0 disk to available status again, execute the following command:
root@solaris11-1:~# zpool detach mir_pool c8t14d0
root@solaris11-1:~# zpool status mir_pool
pool: mir_pool
state: ONLINE
scan: resilvered 64.5K in 0h0m with 0 errors on Fri Jul 04 00:41:28 2014
config:
NAME STATE READ WRITE CKSUM
mir_pool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c8t5d0 ONLINE 0 0 0
**c8t6d0** **ONLINE** 0 0 0
spares
**c8t14d0** **AVAIL**
ZFS wins again!
See Also
Here are some links to other things I've written:
And here are some Oracle Solaris 11 resources:
About the Author
Alexandre Borges is an Oracle ACE in Solaris and has been teaching courses on Oracle Solaris since 2001. He worked as an employee and a contracted instructor at Sun Microsystems, Inc. until 2010, teaching hundreds of courses on Oracle Solaris (such as Administration, Networking, DTrace, and ZFS), Oracle Solaris Performance Analysis, Oracle Solaris Security, Oracle Cluster Server, Oracle/Sun hardware, Java Enterprise System, MySQL Administration, MySQL Developer, MySQL Cluster, and MySQL tuning. He was awarded the title of Instructor of the Year twice for his performance teaching Sun Microsystems courses. Since 2009, he has been imparting training at Symantec Corporation (NetBackup, Symantec Cluster Server, Storage Foundation, and Backup Exec) and EC-Council [Certified Ethical Hacking (CEH)]. In addition, he has been working as a freelance instructor for Oracle education partners since 2010. In 2014, he became an instructor for Hitachi Data Systems (HDS) and Brocade.
Currently, he also teaches courses on Reverse Engineering, Windows Debugging, Memory Forensic Analysis, Assembly, Digital Forensic Analysis, and Malware Analysis. Alexandre is also an (ISC)2 CISSP instructor and has been writing articles on the Oracle Technical Network (OTN) on a regular basis since 2013.
| Revision 1.0, 03/05/2015 |
Follow us:
Blog | Facebook | Twitter | YouTube