Advanced Database Troubleshooting Tools, Part 3
by Przemyslaw Piotrowski
The previous two parts of this series walked through enterprise- and database-level methods for managing ephemeral database problems and dedicated ways to address them in a highly systematic approach. This part completes the troubleshooting portfolio with tools for tackling symptoms surfacing through the wait Interface, cluster, operating system, and client layers.
See Also:
Introduction
As much as SQL statements are related to performance, clustering is all about availability—protecting databases against all sorts of failover scenarios by introducing a single gain: redundancy. Regardless of how many well-engineered components are put into a system, it is just a matter of time before a failure occurs, and this unit of time is dubbed the mean time between failures (MTBF). Once there is a failover situation, another important metric is the mean time to recover (MTTR), which involves restoring service levels to their original point as soon as possible.
Oracle Database features ensure minimal business interruption during failure through the deployment of Oracle Real Application Clusters (Oracle RAC), Data Guard standby, Oracle Automatic Storage Management (Oracle ASM), Oracle Recovery Manager (Oracle RMAN), Global Data Services (GDS), Oracle Flashback, and Application Continuity. Engineering for high availability means securing the system before failures surface so that MTTR can be minimized or failures can even be eliminated completely.
Network connectivity, client error handling, and operating system problems on any endpoint can have a disastrous impact on availability as well. Proper validation and instrumentation of these layers is no less important than instrumentation of the database itself. Read on to familiarize yourself with recent developments in troubleshooting the database stack from both ends.
Wait Events
Wait events, often simply called events, are used to measure where time is being spent inside the database. This includes time spent sitting idle and doing actual work, so that overall activity can be broken down into individual components for analysis. Transient database problems will frequently spike on the Active Session History (ASH) chart under certain wait event classes that bundle hundreds of individual events from every database activity, meaning that Oracle's wait interface is complete and instrumented throughout the database kernel.
The major classification of the classes with the most common wait events is as follows:
- Administrative (backups and index rebuilds)
- Application (locks)
- Cluster (Oracle RAC Cache Fusion activity)
- Commit (log file sync)
- Concurrency (index contention, library cache, buffer busy)
- Configuration (high watermark contention, sequence contention, redo switching, checkpoints)
- Idle (SQL*Net messages from the client, parallel execution orchestration, timers)
- Network (SQL*Net messages and other data to the client, Data Guard transport)
- Other (buffer busy, flashback, Oracle RAC DRM and a mixture of other unclassifiable events)
- Scheduler (resource manager throttling)
- System I/O (Oracle RMAN backup activity, sequential and parallel I/O on control files and log files, parallel writes on data files)
- User I/O (data file activity, direct path operations, reads by other sessions)
Even if that list seems comprehensive and thorough, it is still only a wait interface, and operations on the CPU or run queue are not waits. That being said, a properly configured database (with just green on the Oracle Enterprise Manager performance graph) will ignore the usability of the wait interface until a problem comes up and the picture becomes polluted by a bottleneck.
Wait events will require careful analysis in the Automatic Workload Repository (AWR) reports and SQL trace files. Fortunately, a number of helpful resources exist that can aid in troubleshooting problems that show up through the wait interface, with the most authoritative one being the Performance Tuning Guide from the product documentation. For customers who have a current My Oracle Support subscription, the best shot would be the Oracle Performance Diagnostic Guide available from My Oracle Support Note 390374.1, which combines knowledge about recovering from underperforming queries, hangs, or locks and overall performance degradation. Although the process documented in the guide is not automated at all, it provides solutions to common problems together with their effort and risk categorization so that preventive measures can be put into place before implementing them.
In addition, for even the most experienced professionals, the information provided in the Real-World Performance Learning Library section of the Oracle Learning Library can be striking. Other useful tools for targeting particular wait events include the following:
- For log file sync, log file switch completion, and log file parallel write, see "Log File Sync Diagnostic Information (LFSDIAG)" in My Oracle Support Note 1064487.1.
- For gc current block request, gc buffer busy acquire, gc cr block grant 3-way, gc cr block congested, and gcs drm freeze in enter server mode, see "Script to Collect RAC Dynamic Resource Re-mastering Information (DRMDIAG)" in My Oracle Support Note 1492990.1.
- For enq: TX – contention; enq: TM – contention; and enq: HW – contention, see "Troubleshooting Database Contention With V$Wait_Chains" in My Oracle Support Note 1428210.1.
- For LGWR wait on LNS, LNS wait on LGWR, ARCH wait on ATTACH, and LGWR wait on SENDREQ, see "Data Guard Physical Standby – Configuration Health Check" in My Oracle Support Note 1581388.1.
Clustering
After making a database performant, it's time to take care of availability. In the real world that doesn't happen without the deployment of Oracle RAC, a clustered way of running a database across one or more nodes.
For a database, clustering can cause performance problems for Cache Fusion—a diskless cache coherency mechanism in Oracle RAC—when an application is not architected or configured properly with Oracle RAC–awareness or affinity. From an availability standpoint, even under the Oracle Maximum Availability Architecture, there will be times when redundancy kicks in but a cluster configuration still requires after-the-fact troubleshooting to determine the reason for a failure and to restore the original service-level safeguards.
Between the Oracle RAC Server Control (SRVCTL) utility and the Oracle Clusterware Control (CRSCTL) utility, which are shown in Figure 1, it is CRSCTL that can—in addition to taking actions on cluster resources—also debug various Oracle Clusterware components. The CRSCTL DEBUG command allows you to dynamically set debugging flags on the Cluster Ready Services (CRS), Oracle Cluster Registry (OCR), Event Manager (EVM), and Cluster Synchronization Services (CSS) subcomponents that can be listed with the CRSCTL LSMODULES command. If debug information from OCR isn't helpful, further analysis can be done using the OCRDUMP and OCRCHECK utilities. OCRDUMP can assist in dumping entire the OCR into a flat file for diagnosis, and OCRCHECK provides a way to validate OCR integrity.

Figure 1. Grid Infrastructure and Oracle Automatic Storage Management troubleshooting frameworks.
ORAchk has already covered the verification of the cluster's static configuration, so another step is run-time examination using the Cluster Verification Utility (CVU or CLUVFY). CVU was initially developed as a downloadable add-on that required separate installation, but later it was incorporated into the Oracle Clusterware home. CVU is the functionality that is used to run Oracle Universal Installer's checkups and fix-up scripts. Figure 2 shows the CVU options.
CVU runs in three primary modes that correspond to active and proactive efforts:
- Component mode (active) is for checking individual cluster components such as node connectivity, free space, Oracle Automatic Storage Management Cluster File System, Oracle Local Registry, Single Client Access Name (SCAN), and so on.
- Pre-stage mode (proactive) handles a series of prechecks prior to installing, reconfiguring, and upgrading databases and clusters.
- Post-stage mode (proactive or active) is responsible for validating the database stack's health after installation, upgrade, or reconfiguration.
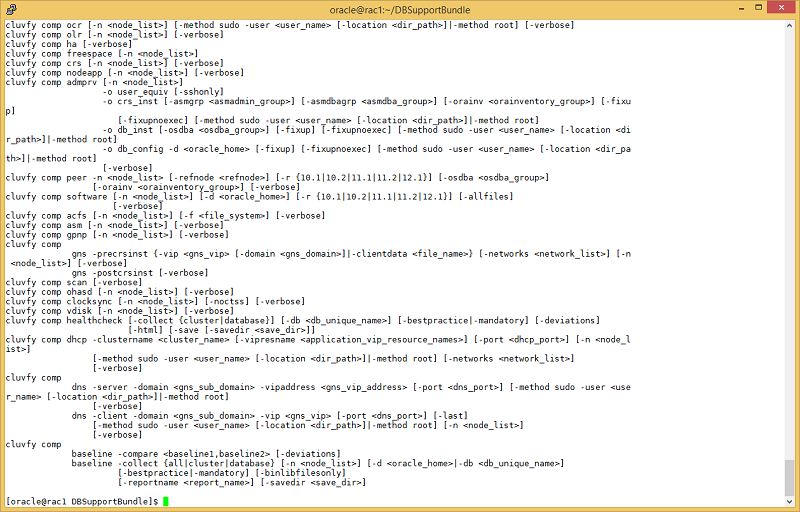
Figure 2. Excerpt showing the compute options from the Cluster Verification Utility.
For cases where proactive and active means are insufficient and problems persist despite having taken the previously explained steps, the single reactive tool to use would be the Trace File Analyzer Collector (TFA), shown in Figure 3, which ships with Oracle Grid Infrastructure 11.2.0.4, 12.1.0.1, and later. (For previous releases, it is available as a separate download from My Oracle Support Note 1513912.1.)
There are several ways that using TFA surpasses collecting manual logs, either for internal scrutiny or for Oracle Auto Service Request. Mainly, it reduces the time required to gather logs, but it also reduces the amount of data collected to bare minimum. TFACTL DIAGCOLLECT is the command for managing and orchestrating collections across entire clusters, whereas TFACTL ANALYZE is used to perform rapid error pattern analysis.
Figure 3. Trace File Analyzer Collector with diagnostics collection for Oracle RAC 12.1.0.2.
There is an integrated component of Oracle Clusterware called Cluster Health Monitor (CHM) that can be used for collecting real-time cluster-wide data, but in reality it is usually used for the post-mortem diagnosis. It is a framework for assembling real-time operating system metrics intro a central location. CHM consists of the System Monitor Service (osysmond), which is on every cluster node that receives online system information, and one Cluster Logger Service (ologgerd) for every 32 nodes, which pulls data from the System Monitor Service into the central Oracle Grid Infrastructure Management Repository, which resides in the same disk group as OCR in Oracle Grid Infrastructure 12_c_.
Retaining the high availability of an Oracle RAC cluster is especially important within the context of scheduled maintenance, such as patching. A patching procedure can rely on either automated mode or a proactive planning tool such as OPlan, which dictates the exact steps in which to apply patches in the least invasive manner (see My Oracle Support Note 1306814.1). Two tools were developed for addressing patching problems:
Watchmen
If a single tool exists from which Oracle Support will first ask for output when troubleshooting a cluster problem, there is 99 percent chance the tool would be OSWatcher. It is an OS-scheduled job that periodically dumps system statistics into an archive folder for later analysis. The statistics are gathered via the iostat, mpstat, netstat, ifconfig, ps, top, vmstat, meminfo, slabinfo, and prvtnet commands (and from traceroute on the interconnect).
The raw statistics are then retained for a given period of time and later undergo a regular rotation procedure invoked by OSWatcher. OSWatcher is often referred to as OSWbb, because for some time it was called OSWatcher Black Box. The primary note, My Oracle Support Note 301137.1, includes tons of information regarding setup, maintenance, and usage of the tool, including demonstration videos and tutorials.
The collected data is also useful because another tool, OSWatcher Analyzer (shown in Figure 4), uses it directly. Not only does this tool allow for graphing the archives, but it is also capable of handling automated analysis of the system's state, effectively reducing troubleshooting time to a bare minimum. In reality, it is no longer optional on the Oracle Database stack, and there are streamlined means for getting this permanently onto the system through the OS services framework (see My Oracle Support Note 580513.1).
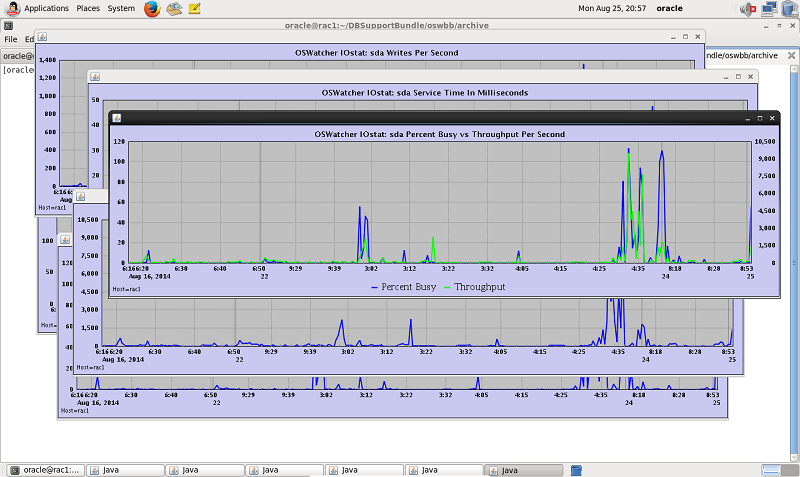
Figure 4. OSWatcher graph mode.
The V$WAIT_CHAINS performance view is one way to tackle concurrency issues when problem occurs making it a great active, but somewhat lacking proactive, tool. There is no way to dig into wait chains and error stacks after the problem ends, unless another indispensable tool is deployed.
Procwatcher is a background OS job that collects stack traces of Oracle Database processes that are running into race conditions such as enqueue, latch, or mutex contention. It can be deployed in either standalone or Oracle Clusterware mode as a cluster resource and will cyclically plug into Oracle Grid Infrastructure and Oracle Database and dump their wait chains, which can be priceless during the analysis of concurrency, hang, eviction, performance, or even backup issues. Its deployment script is also its configuration script, which contains dozens of parameters that can be used to lower Procwatcher's impact on the system or increase the collected level of details, as needed. The latest version of Procwatcher is available from My Oracle Support Note 459694.1.
While some of the OSWatcher data can be, and usually is, collected with operating system instrumentation, there is absolutely no way to dig into database short stacks afterward. Some obvious issues, such as deadlocks, will show up elsewhere, but most of the concurrency and contention data is lost or persists as a vague approximation. Active Session History (ASH) or Automatic Workload Repository (AWR) ASH data can be used to pull wait chains but not the short stacks that are very helpful in diagnosing more-challenging problems.
Troubleshooting Oracle Automatic Storage Manager
Oracle Automatic Storage Management (Oracle ASM) has become a necessary and indispensable component of the Oracle Grid Infrastructure stack starting with Oracle Database 11_g_ Release 2. Following its inclusion in the Oracle Maximum Availability Architecture, a lot of resources were invested into making Oracle ASM resilient against a number of problems, and the Oracle ASM instrumentation doesn't lag behind that of the database at all. For regular LUN issues, stick with the operating system methods of troubleshooting, but for the Oracle ASM stack, a number of different tools exist to assist in diagnosing problems with disks, disk groups, and volumes.
The Server Control Utility (SRVCTL), which is used to administer the database components of a cluster, is a good initial tool for checking the online status of various Oracle ASM parts and also to control its state and modify startup options. If for some reason, SRVCTL is unable to communicate with CRS, the SRVM_TRACE operating system variable should be set to TRUE to enable debugging.
The Oracle Automatic Storage Management Command-Line Utility (ASMCMD) is a wrapper that controls and displays the status of various Oracle ASM components and has the ability to quickly outline storage information and statistics in a human-readable format. When ASMCMD has problems connecting to the instance or performing certain operations against disks, it might be needed to debug internal commands, similar to SRVCTL, through the operating system debug variable DBI_TRACE=1, which then echoes individual SQL statements triggered from ASMCMD.
Kernel Files OSM Disk (KFOD) is a tool used by Oracle Support—but also by the Oracle Universal Installer, the Database Configuration Assistant (DBCA), and the Oracle ASM Configuration Assistant (ASMCA)—for disk group discovery, which has become a somewhat sensitive subject over the years because many prerequisites must be met to detect them seamlessly. Before jumping into messing with ASM_DISKSTRING, it can be beneficial to pull the KFOD execution line from the configuration logs and run KFOD manually, ORACLE_HOME and LD_LIBRARY_PATH must be then set to the /tmp/OraInstall location. KFOD allows you to experiment with various ASM_DISKSTRING settings so that a proper setting can be selected immediately in the Oracle Universal Installer.
The Kernel Files Metadata Editor (KFED) is much more invasive than KFOD, because it can read and write Oracle ASM disks. Therefore it should be used only under Oracle Support guidance. KFED can assist in a series of problems around ORA-15* errors that show up when an Oracle ASM instance has problems mounting or interacting with disk groups.
The Oracle ASM Metadata Dump Utility (AMDU) is one of the most useful tools for recovering from severe Oracle ASM failures, because it's able to extract files from unmounted disk groups just by providing their locations pulled from a metadata dump. As the first step, a dump of metadata is performed so that the locations of individual files residing on Oracle ASM can be traced, and then the locations are used to extract raw datafiles to disk. There is a steep learning curve for becoming proficient with AMDU, because the metadata is not immediately decipherable, but when Oracle ASM fails to mount disk groups due to some austere conditions, this tool will be instrumental.
KFOD, KFED ,and AMDU are documented under My Oracle Support Note 1485597.1 and ship as part of Oracle Grid Infrastructure 11_g_ Release 2 and later.
The Oracle ASM Space Reclamation Utility (ASRU) works in conjunction with storage thin provisioning to reclaim space on disk groups through resizing and zero-filling free space spread across three phases: compaction, deallocation, and expansion. When dropping tablespaces or whole databases from disk groups has no effect on thinly provisioned storage, this is the way to proceed to troubleshoot space reclamation. ASRU can be downloaded from the Oracle Cloud Storage page on the Oracle Technology Network.
For collecting troubleshooting information on Oracle ASM, there is a set of My Oracle Support documents called Service Request Data Collections (SRDCs). These are the guidelines for pulling required files that can be later uploaded to Oracle Auto Service Request for diagnosis. SRDCs will list the Trace File Analyzer (TFA) as the first resort for diagnostic collection, but they offer alternative ways of gathering trace data if TFA is missing from the system.
Clients
As problems get pushed down the stack from the site, cluster, and database level to the client level, several techniques exist that can effectively diagnose application connectivity issues. Regardless of whether the client uses the JDBC Thin client driver or Oracle Call Interface, each is heavily instrumented and can dump extensive trace data that provides insight into the details of communication with the database server at a low level.
SQL*Net is the communication protocol between the database server and clients. Its trace can be enabled on the server side (listeners and cluster manager [CMAN]) or the client side (Oracle Call Interface, Open Cloud Computing Interface [OCCI], JDBC, and the TNSPING utility). Server-side tracing is enabled through listener.ora or cman.ora, while client-side tracing is handled by setting the appropriate parameters in sqlnet.ora when dealing with Oracle Call Interface and by setting the oracle.jdbc.Trace=true flag when JDBC is involved.
For JDBC, ojdbc5_g.jar or ojdbc6_g.jar must be used, because these JAR files contain logging instrumentation that is not present in the standard ojdbc5.jar and ojdbc6.jar modules.
Starting with Oracle Database 11_g_ Release 2, the client diagnostic location has been merged into the Automated Diagnostic Repository (ADR) base, so whatever is dumped from the client will safely land under the diag directory. There are very few occasions on which raw SQL*Net/JavaNet trace files become immediately self-explanatory, so they usually need to go through the TRCSESS tool, which preprocesses raw data into highly readable reports. TRCSESS can go over connectivity, Two Task Common (TTC), and SQL details, including detailed byte-for-byte communication statistics.
A recent enhancement to the JDBC stack and now a de facto standard implementation of a shareable pool, Universal Connection Pooling (UCP) comes with extensive functionality that can be tricky to debug on the database-side alone. The connection borrowing, harvesting, caching, and reclamation offered by UCP will sometimes require additional debugging information that can be pulled three ways: through pool statistics returned from PoolDataSource.getStatistics(), through Oracle RAC statistics from OracleJDBCConnectionPoolStatistics.getStatistics(), or via the logging interface's oracle.ucp.level property (INTERNAL_ERROR to FINEST). An alternative way to enable UCP debugging is through the UniversalConnectionPoolManagerImp JDBC class by invoking the UniversalConnectionPoolManager.setLogLevel() procedure.
The Big Picture
Before running into problems, a systematic approach for meeting service-level agreements (SLAs) is best addressed through the deployment of ORAchk, TFA, CVU, OSWatcher, and Procwatcher. During transient database problems, a mature toolset consisting of Automatic Database Diagnostic Monitor (ADDM), ASH, SQL Monitor, SQL Health Check (SQLHC), and SQL/optimizer traces will aid in the fastest gathering of information required for resolution. Equally important on an after-the-fact situation when the problem is gone but still causes a severe impact on the database's availability or performance, is the use of ADDM, AWR, OSWatcher, and Procwatcher. A complete package of these tools can be easily obtained through the DB Support Tools Bundle from My Oracle Support, which is available in My Oracle Support Note 1594347.1 (updated with recent releases of the tools).
Oracle Enterprise Manager can approach problems at any stage, proving equally useful in proactive monitoring and responsive troubleshooting across the stack. Because Oracle Enterprise Manager is far more than just a collector or monitor, its deep integration with the database allows you to act on problems directly. This integration includes features for both the performance and availability layers. Note that with Oracle Database 12_c_, the familiar Oracle Enterprise Manager Database Control has been discontinued in favor of Oracle Enterprise Manager Database Express (shown in Figure 5), which is now completely isolated from the Oracle Enterprise Manager Cloud Control product line. Nevertheless, smaller shops are likely to seek this tool for managing single-instance setups.
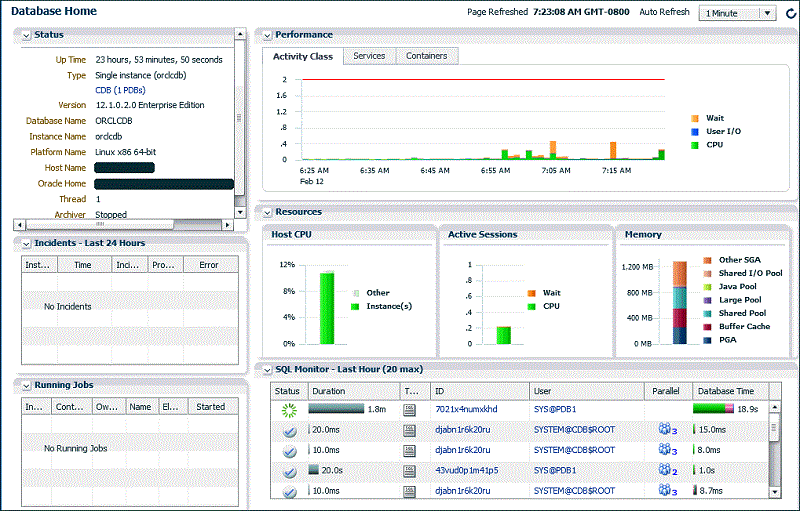
Figure 5. Oracle Enterprise Manager Database Express 12_c_.
Conclusion
Because the industry is on the verge of cloud and in-memory revolutions, a lot of new complexity will occur around databases to accommodate these new paradigms into existing architectures without sacrificing today's speed and uptime. Driving factors will have to shift between consistency and performance, isolation and redundancy, as well as durability and latency. Having the know-how for diverse tools that are targeted at expert troubleshooting of each layer can only increase in importance given how deep and tight the entire stack will become.
About the Author
Przemyslaw Piotrowski is a principal database administrator with more than 10 years of experience developing, architecting, and running mission-critical databases for a number of industries. He is an Oracle Database Certified Master and an Oracle Certified Expert for Oracle RAC, Performance Tuning, and SQL specializing in Oracle Maximum Availability Architecture and real-world performance patterns. As a regular Oracle Technology Network columnist, he publishes information about databases, tools, and programming languages.