Advanced Database Troubleshooting Tools, Part 1
by Przemyslaw Piotrowski
The strategy for approaching Oracle Database problems tends to vary between features, setups, and software stacks. Smart selection of troubleshooting tools is fundamental to resolving issues that impact a database directly or through specific components across a configuration. The idea behind systematic troubleshooting is that you can decide when and where to invest effort by introducing proactive means in contrast to firefighting, which is always a reactive experience.
See Also:
Introduction
The full technology stack around the database spans from applications and middleware, through operating systems and hypervisors, and up to servers, networking, and storage. With so many moving parts, it is crucial for anyone accountable for the stack to be able to quickly examine each piece. Oracle Database administrators benefit from immense database instrumentation across the entire stack, which is essential to the ongoing success of Oracle Database as a product.
Being able to break down problem silos into smaller parts and picking proper tools to debug issues are some of the most sought-after skills in the industry. This series introduces a holistic approach for selecting the right tools for mixture of different problems that affect databases throughout the entire stack. Covered are both tools that ship with the database software media and resources available to users who have a current My Oracle Support subscription.
The series is divided into three parts:
- This first part explores the entire database stack.
- The second part covers troubleshooting problems at the database, instance, and SQL statement level.
- The third part is about troubleshooting the wait interface, cluster, and client.
Because each troubleshooting tool addresses different needs at different levels, a distinction can be made based on their type: proactive (running prior to an error occurrence), active (executed while the issue lasts), and reactive (after-the-fact investigation). Furthermore, a distinction can be made based upon their class: report, utility, bundle, advisor, assistant, daemon, collector, analyzer, checker, monitor, watcher, or profiler.
The Layers of the Database Stack
Figure 1 shows the entire database stack broken down into separate layers; the operating system and applications have been skipped for clarity. Some of the introduced tools span more than one layer and can facilitate multiple emergency scenarios. While some experts prefer staying with native operating system trace commands and plain SQL or SQL trace, much time can be invested elsewhere by leveraging specialized tools.
Throughout this series, a systematic troubleshooting methodology is introduced in a way that is far from being just reactive but also is proactive by incorporating a means of securing against problems before they happen.
Note that special care must be taken prior to running any of the tools, because even common ones such as the Automatic Workload Repository (AWR) of Oracle Database can cause severe impacts. When in doubt, contact Oracle Support first.

Figure 1. Database troubleshooting framework layers.
Methodology, Measurement, and Math
All ongoing processes are characterized by certain acceptance criteria, which deem them to be satisfactory or unacceptable. For databases, these criteria come down to availability and performance, effectively leaving every other factor as just a derivative. The successful maintenance of a responsive, 24/7 database system comes at the cost of a certain degree of complexity that arose through decades of engineering. Effectively managing that sophistication in a highly streamlined way means understanding the layout of the entire stack and using the proper tools.
One of the biggest challenges of productive troubleshooting is recognizing cause from effect—in a highly sophisticated system, these tend to overlap and diffuse, leaving the chances of responding with an accurate diagnosis at first shot relatively low. Because the stack is far from flat and issues cut across deeply, timestamps are rarely a way to determine the original reason for a problem.
At times, great experience with a certain class of problems can mislead a troubleshooting expert into discovering familiar patterns that are not actually applicable to the particular system. The iterative nature of the process means that at any step, there is a need to measure impact and to minimize the risk of introducing changes to a live system. The general troubleshooting algorithm is fairly straightforward: find the worst bottleneck or problem, fix it, measure whether the service level is acceptable and, if it is not, repeat the process from the beginning.
Holistic troubleshooting means approaching problems in a highly organized and systematic manner across the entire stack and between components. Problems that occurred on one system can be mitigated throughout the entire environment by establishing a set of best practices for preventing issues prior their occurrence anywhere. Thinking about availability and performance, it's equally important to remember that changes introduced within an application architecture will generally surpass database-only efforts. So, it's crucial to build a wider perspective into the problem and only then drill down into individual pieces.
Enterprise Management
No more-comprehensive or versatile tool exists to date that covers the entire database stack, including third-party layers, with cataloging, provisioning, monitoring, and complete end-to-end management lifecycle than Oracle Enterprise Manager. The 12_c_ release can automate running a full database stack and provides interfaces on top of the latest features (see Figure 2), such as Real-Time Automatic Database Diagnostic Monitor (ADDM), AWR Warehouse, or Active Session History (ASH) 3-D analytics.
Together with the capability of seamlessly managing hundreds of targets, Oracle Enterprise Manager is fully integrated with incident management, and much of corporate IT Service Management (ITSM) can now flow through Oracle Enterprise Manager directly. Its repository contains full picture of the IT inventory, so if its use is planned and executed with enough coverage, it can be a great help in capacity planning and trend discovery.
In terms of classification, Oracle Enterprise Manager is best of breed, and it can act on forthcoming, current, and past issues.
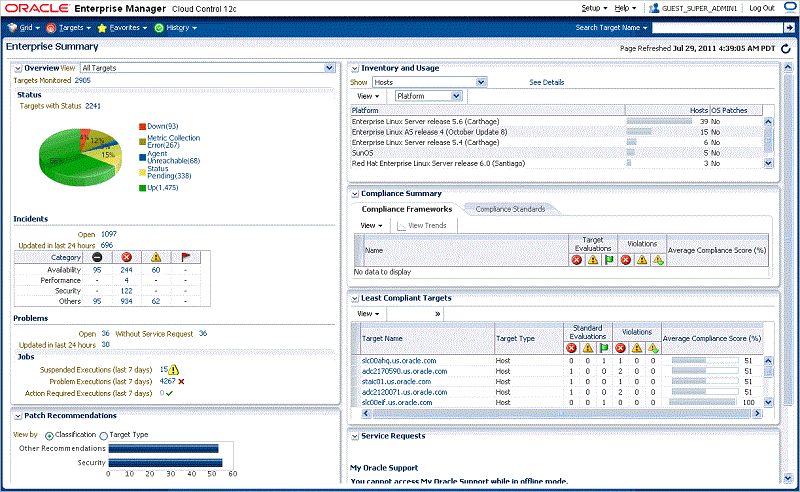
Figure 2. Oracle Enterprise Manager Database Home dashboard.
When deployed in a mission-critical environment, Oracle Enterprise Manager frequently becomes the most relied-upon framework for managing service levels and incidents and, thus, requires more engineering around its high availability, which can span four levels, from a standalone configuration to a full Oracle Maximum Availability Architecture. That criticality requires the use of different tools to diagnose the agent, service, and repository.
While emctl is the primary utility for validating proper functioning of the management agent and service at a high level, the Enterprise Manager Diagnostics Kit might be needed to solve more-complex issues (see My Oracle Support Note 421053.1). The kit comprises three active tools for troubleshooting each component of the Oracle Enterprise Manager ecosystem:
repvfy for diagnosing repository database problems. It is already embedded within the Oracle Enterprise Manager Cloud Control 12_c_ Support Workbench but can also function standalone. It can pinpoint some known issues but also can be used to dump certain parts of the repository, which is difficult to query (see My Oracle Support Note 1427365.1).agtvfy for troubleshooting issues at the management agent level. It will search for the signatures of known issues and also dump managed targets, which is perfect for a comparison of failing and operational targets (see My Oracle Support Note 1375428.1).omsvfy for inspecting the Oracle Management Service configuration (see My Oracle Support Note 1374945.1).
Oracle Management Repository (OMR) is one of the most overlooked Oracle Enterprise Manager components. It gives immediate SQL access into the state of entire database stack across the enterprise. Management Repository Views encompass a standardized way to access Oracle Enterprise Manager information through custom queries. A single query dissecting an entire database deployment—including hardware, clusterware, and the OS layers—could be as simple as the query shown below, which takes list of target database nodes as input for the SQL PIVOT operation:
SQL> select * from (
select 'HW' cat, r.db_instance_name target_name, 'Hardware' name, h.system_config value
from mgmt$os_hw_summary h, mgmt$rac_topology r where h.host_name=r.rac_node_name
union all
select 'HW', r.db_instance_name, 'Serial#', h.system_serial_number
from mgmt$os_hw_summary h, mgmt$rac_topology r where h.host_name=r.rac_node_name
union all
select 'HW', r.db_instance_name, 'CPU/Cores', h.physical_cpu_count||'/'||h.logical_cpu_count
from mgmt$os_hw_summary h, mgmt$rac_topology r where h.host_name=r.rac_node_name
union all
select 'HW', r.db_instance_name, 'Memory', to_char(h.mem)
from mgmt$os_hw_summary h, mgmt$rac_topology r where h.host_name=r.rac_node_name
union all
select 'DBINIT', p.target_name, p.name, p.value
from mgmt$db_init_params p where p.isdefault='FALSE'
union all
select 'CRS', r.db_instance_name, t.property_name, t.property_value
from mgmt$target_properties t, mgmt$rac_topology r
where t.target_type='cluster' and t.target_name=r.cluster_name and t.property_name in ('CRSVersion', 'scanName', 'OracleHome')
union all
select 'DB', t.target_name, t.property_name, t.property_value
from mgmt$target_properties t where t.target_type='oracle_database'
and t.property_name in ('OracleHome', 'StartTime', 'OpenMode', 'RACInstNum', 'AdrHome', 'DBVersion', 'RACOption')
union all
select 'REDO', l.target_name, 'Redo', count(*)||' x '||l.members||' x '||l.logsize
from mgmt$db_redologs l where l.target_type='oracle_database' group by l.target_name, l.members, l.logsize
union all
select 'OSKERNEL', r.db_instance_name, o.name, o.value from mgmt$os_kernel_params o, mgmt$rac_topology r
where r.rac_node_name=o.host and o.value is not null and o.name not like 'net.ipv%'
union all
select 'OS', r.db_instance_name, t.property_name, t.property_value from mgmt$target_properties t, mgmt$rac_topology r
where t.target_type='host' and t.target_name=r.rac_node_name
)
pivot (
max(value)
for target_name in ('ORCL1_1', 'ORCL1_2', 'ORCL1_3', 'OEMP11', 'OEMP12')
)
order by cat, name
/
Diagnostic Assistants, Configuration Management, and Service Requests
The functionality to drill down into individual components from Oracle Enterprise Manager is just the tip of the iceberg, because the tool itself was designed to provide direct integration with My Oracle Support and embedded incident management, as shown in Figure 3. Many of the proactive features of Oracle Enterprise Manager are integral components.
The tools mentioned in this section fall into the configuration management basket, which encompasses various means of inspecting, analyzing, and packaging incidents and problems, in preparation for guided self-service or external intervention. In their full extent, they allow for the complete automation of problem diagnosis and resolution, following a deep integration with the My Oracle Support portal.
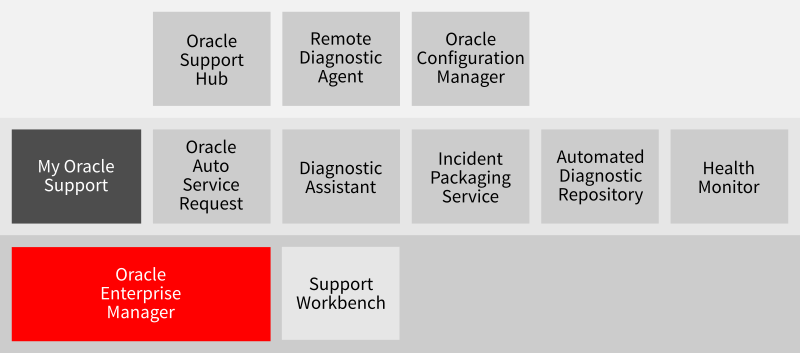
Figure 3. The Oracle Enterprise Manager and My Oracle Support ecosystem.
Automated Diagnostic Repository (ADR) was introduced in Oracle Database 11_g_ to unify common logging and diagnostic locations among various components of the Oracle software stack, providing a central repository for log, trace, and incident files. ADR works at the level of issues and problems that can be easily packaged and sent to Oracle Support through the Incident Packaging Service (IPS), which is a way to quickly pull all problem-related files from the environment. It is also tightly integrated with the Oracle Enterprise Manager Support Workbench, which provides a graphical interface on top of ADR and Oracle Configuration Manager. ADR can also trigger Health Monitor (HM) checkers in response to certain problems where HM is able to run a series of integrity validations against data blocks, redo logs, the dictionary, and such. Reports from HM runs are then stored inside ADR but can be accessed from Oracle Enterprise Manager, ADR, or the DBMS_HM package.
Oracle Configuration Manager is designed to collect and continuously push configuration data to My Oracle Support, which can then undergo automated analysis and provide better resolution times than would be achieved through manual back-and-forth communication with a support engineer. While it can also function in disconnected mode, it gains extra functionality such as drafting Service Requests (SRs) and collecting information from a number of components ranging from hosts, applications (for example, Oracle's JD Edwards, PeopleSoft, Siebel, and Hyperion applications), and databases up to application servers and engineered systems.
Oracle Support Hub (OSH) is a central component for providing a tunnel into My Oracle Support for all Oracle Configuration Manager deployments across the environment (see My Oracle Support Note 1304614.1). When no proxy is available on the network that can be provided to Oracle Configuration Manager, Oracle Support Hub will act as a midpoint.
Remote Diagnostic Assistant (RDA), which is shown in Figure 4, collects data from an impressive subset of Oracle's software stack, including all variants of Oracle Database deployment (single instance, standby, cluster, and clustered file systems) and both Standard and Enterprise editions, plus all sorts of applications and servers. It pulls configuration information from all detected components to quickly diagnose problems or provide diagnosis information that would be difficult to collect manually. RDA comes bundled with Oracle Configuration Manager (see My Oracle Support Note 314422.1) and in a number of different bundles. As of today, no other tool gives better insight into the configuration across an entire environment.
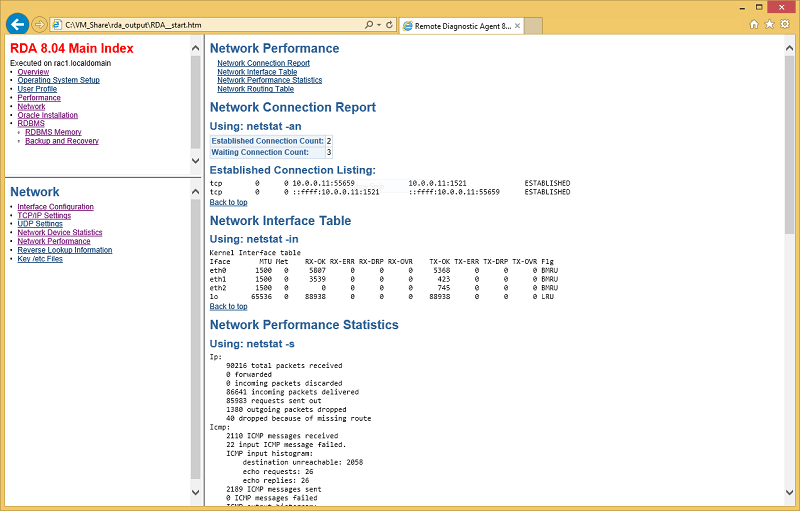
Figure 4. Network section of the RDA report.
Oracle Auto Service Request is available to Oracle Premier Support customers and assists in automated problem resolution on Oracle hardware, including servers, storage, and engineered systems (list of qualified products). It proactively dispatches a Service Request to My Oracle Support upon detecting faulty component in order to either initiate troubleshooting or possibly order a replacement.
Diagnostic Assistant (DA) wraps around many of the mentioned support tools (including but not limited to ADR, Oracle Configuration Manager, and RDA) to provide a seamless menu-driven command-line interface for invoking checks and organizing collections, packaging incidents, and interacting with Oracle Support. When you are unsure about how to organize diagnostic collection, this tool should be chosen for guided analysis. DA does not require a separate download because it is always bundled with RDA.
The entire diagnostic ecosystem around ADR, IPS, Oracle Configuration Manager, RDA, Oracle Auto Service Request, and Oracle Enterprise Manager changes the current approach to the maintenance of vast database environments by providing an automated, resilient and—most importantly—proactive means of retaining superb service levels at scale. As it turns out, the amount of maintenance effort will usually be on par between a proactive and reactive approach, but there will be a difference in availability and performance. Through the immense portfolio of support-assisting tools, there is now huge flexibility in making that call.
Health Checks for the Oracle Stack
Very few tools received more attention than recent releases of ORAchk, Oracle's flagship tool for troubleshooting database and other components of the stack. (RACcheck was recently renamed to ORAchk and now also incorporates Exachk.) Not only does it collect a healthy amount of system information, but it also provides extensive recommendations according to the latest best practices from internal expertise groups.
ORAchk reports, such as the one shown in Figure 5, prove their value exceptionally fast by breaking down each check into a subscore and supplementing each recommendation with an explanation and further references. Every ORAchk report has a timer that limits the validity of all included recommendations to 90 days from the release of particular ORAchk version. This means that, at most, every 90 days a newer, improved version is made available that includes an updated and expanded checklist and includes even Patch Set Updates and recommended interim patches.
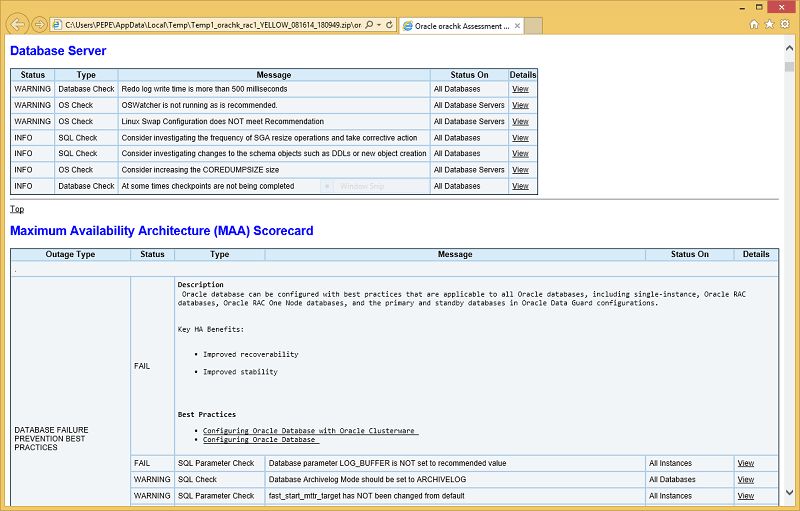
Figure 5. ORAchk report with RDBMS checks and Oracle Maximum Availability Architecture Scorecard.
ORAchk 2.2.5 runs with a number of interesting properties, such as the following:
- Oracle Maximum Availability Architecture Scorecard is an essential element of every ORAchk report. For each of hundreds of checks, it adds or deducts points depending on whether a check returns a failure, a warning, or information or it gets skipped. That score is then mapped onto a 0–100 scale and represents a strong ballpark figure for estimating overall system health.
- By default, Oracle Maximum Availability Architecture Scorecard is considered within the overall scorecard, so unless a system is deployed within the Oracle Maximum Availability Architecture blueprint, lots of checks will fail. This section includes best practices for engineered systems, Oracle Real Application Clusters (Oracle RAC), a standby site, backup and recovery, storage redundancy, data corruption, and high availability.
- The Upgrade Readiness mode of ORAchk runs a complete health check prior to upgrading Oracle Database 11.2.0.3 or later. Successfully passing this report means better upgrade performance with far fewer issues. Because it is a fully noninvasive examination, there is absolutely no reason for not running this as part of the upgrade plan.
- Collection Manager (see Figure 6) is a central repository for uploading ORAchk outputs that is accessible through an Oracle Application Express–built front end. This allows cross-reporting for compliance with certain corporate standards or best practices and gives instant hints on misconfigured systems.
- Silent Mode provides a possibility to make a run of ORAchk completely scripted (in contrast to the default interactive mode). Before automating its run through the OS, it's worth looking at the Daemon Mode, though (see the next paragraph).
- Daemon Mode provides a means for the automatic execution of ORAchk at a repeating interval, together with instant e-mail notification of the problems identified or any problems running ORAchk itself. Multiple difference modes can be scheduled simultaneously, so that check domains can be isolated from each other.
- Comparison functionality brings incredible power to unify an entire environment, because different setups can be instantly compared and validated against the latest recommendations.
- Merge is a feature of ORAchk that is useful when SSH equivalence cannot be directly leveraged by the
orachk script or when, for other reasons, multiple reports are collected separately from different nodes. This enables putting them back into a full cluster report so that scoring is made at the Oracle RAC level, if applicable.
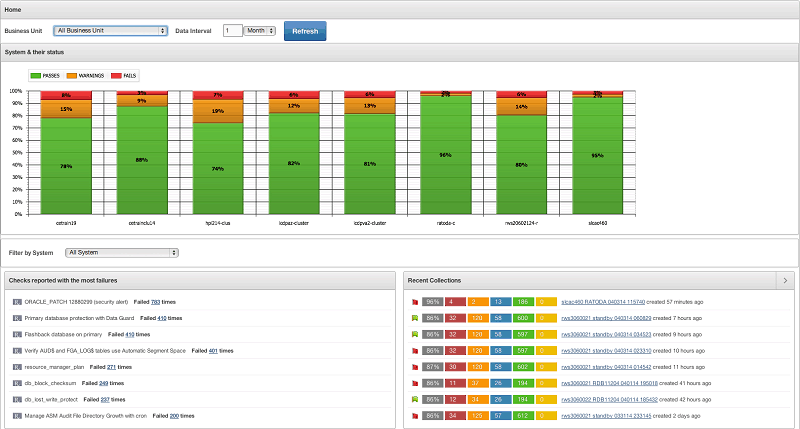
Figure 6. ORAchk Collection Manager home screen.
Forecasting with Oracle Enterprise Manager Cloud Control
Orchestrating database operations around Oracle Enterprise Manager Cloud Control 12_c_ boosts all troubleshooting dimensions through out-of-the-box proactive monitoring templates and quick reactive tools for drilling into individual components, going as far as emergency direct-SGA mode. The introduction of ADR in the 11_g_ release greatly enhanced the ability to build an IT Infrastructure Library (ITIL)–like workflow around database incident management, which can be further fused into My Oracle Support through Support Workbench and Oracle Configuration Manager.
In addition to compliance checks that can be launched from Oracle Enterprise Manager, ORAchk is quickly emerging as a leading tool for validating the health of the entire database layer with probes against the latest best practices and widely adopted Oracle Maximum Availability Architecture blueprints. At the end of the day, a certified, instrumented stack will be less prone to problems and less likely to require reactive treatment.
About the Author
Przemyslaw Piotrowski is a principal database administrator with more than 10 years of experience developing, architecting, and running mission-critical databases for a number of industries. He is an Oracle Database Certified Master and an Oracle Certified Expert for Oracle RAC, Performance Tuning, and SQL specializing in Oracle Maximum Availability Architecture and real-world performance patterns. As a regular Oracle Technology Network columnist, he publishes information about databases, tools, and programming languages.