I have a dataflow, and I have joined few tables and select column which I need final output.
Due to joining process, it is creating multiple rows which are relevant before selecting columns. But after selecting columns, I prefer to have unique rows in output based on columns and rows not on previous join tables.
Any suggestions are appreciated.
Currently when we select columns output is as below image. I expect, output is single row after selecting the column.
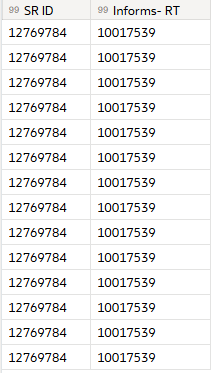
Currently I am using bellow workaround.
Create another workflow with output of first dataset of dataflow.
Add twice same table and union with unique rows to display.
It serves the purpose but repeated work and difficult to manage multiple dataflows.

